Join Order Hints¶
Function¶
Theses hints specify the join order and outer/inner tables.
Syntax¶
Single-layer parentheses (), specifying only the join order. The order of internal and foreign tables is not specified.
leading(join_table_list)
leading(@block_name join_table_list)
Double parentheses (()), specifying the join order and outer/inner tables. The outer/inner tables are specified by the outermost parentheses.
leading((join_table_list))
leading(@block_name (join_table_list))
Single-layer square brackets [], specifying the join order of [] and the sequence of internal and foreign tables.
leading[join_table_list]
leading[@block_name join_table_list]
Combination of single-layer parentheses () and single-layer square brackets [], specifying the join order and the sequence of internal and foreign tables at any layer. The parentheses () specify only the join order, but not the sequence of internal and foreign tables. The square brackets [] specify both the join order and the sequence of internal and foreign tables.
leading(join_table_list1 [join_table_list2])
leading[join_table_list1 [join_table_list2]]
leading[join_table_list1 (join_table_list2)]
leading(@block_name join_table_list1 [join_table_list2])
leading[@block_name join_table_list1 [join_table_list2]]
leading[@block_name join_table_list1 (join_table_list2)]
Important
Single-layer square brackets [] can be used together with single-layer parentheses () to specify the sequence of internal and foreign tables of any layer. Single-layer [] and double-layer () cannot be used together.
Parameter Description¶
join_table_list
Specifies the tables to be joined. The values can be table names or table aliases. If a subquery is pulled up, the value can also be the subquery alias. Separate the values with spaces. You can add parentheses to specify the join priorities of tables.
To prevent semantic errors, tables in the list must meet the following requirements:
The tables must exist in the query or its subquery to be pulled up.
The table names must be unique in the query or subquery to be pulled up. If they are not, their aliases must be unique.
A table appears only once in the list.
An alias (if any) is used to represent a table.
Note
The syntax format of the table is as follows:
[schema.]table[@block_name]
The table name can contain the schema name or block name before the subquery statement block is promoted. If the subquery statement block is optimized and rewritten by the optimizer, the value of block_name is different from that of block_name in leading.
If a table has an alias, the alias is preferentially used to represent the table.
block_name
Specifies the block name of the statement block. It indicates that the hint takes effect in the subquery statement block corresponding to the block name.
Important
By default, a block name is generated for a statement.
CN lightweight statements do not generate block names.
Block names can be generated for the CREATE TABLE AS SELECT, SELECT INTO, SELECT, INSERT, UPDATE, DELETE, and MERGE statements.
The naming rule of a block name is as follows:
A block name is automatically generated for the SELECT, INSERT, UPDATE, DELETE, and MERGE statements. The naming format of a block name for these statements is sel$n, ins$n, upd$n, del$n, and mer$n, respectively, where n starts from 1. The number of statements of different types is not accumulated, but the number of statements of the same type is accumulated.
Example:
INSERT INTO t SELECT * FROM t1 WHERE a1 IN (select * from t2);
--------sel$2-------
-----------------------sel$1----------------------
--------------------------------ins$1---------------------------
Recursively assigns a block name to each statement block before the optimizer is used.
First, assign block names to the existing statements block based on the statement type, then traverse the statement blocks in the following sequence, and assign block name to the statement blocks in the statement blocks:
Traverse the target column.
Traverse the target column in the source table of the MERGE statement.
Traverse actions (update or insert) in the MERGE statement.
Traverse the returning clause.
Traverse the Join and Where conditions in From. (The join condition takes precedence over the Where condition.)
For a set operation, traverse each branch of the set (UNION, INTERSECT, and EXCEPT).
Traverse the HAVING clause.
Traverse the LIMIT OFFSET clause.
Traverse the LIMIT COUNT clause.
Traverse CTE
Traverse the table after From.
Traverse the UPSERT clause.
In the rewriting phase of the optimizer, rewriting optimization is performed due to FUL LJOIN, cte inline, materialized view rewriting, INLIST2JOIN, OR conversion, multi count(distinct), Magic Set, lazyagg, and subquery/sublink promotion, a new subquery is constructed. In this case, the recursive processing during block name assignment is also applied to the newly constructed subquery. The number of block names is accumulated.
In the optimizer rewriting phase, when a subquery is promoted, the table in the inner subquery is promoted to the outer query, and the inner subquery is eliminated. In this case, the promoted table may have the same name as the table in the outer queries. Therefore, the block name to which the promoted table belongs is recorded in the table to distinguish two tables with the same name but are from different query blocks.
For example:
leading(t1 t2 t3 t4 t5): t1, t2, t3, t4, and t5 are joined. The join order and outer/inner tables are not specified.
leading(t1 t2 t3 t4 t5): t1, t2, t3, t4, and t5 are joined in sequence. The table on the right is used as the inner table in each join.
leading(t1 (t2 t3 t4) t5): First, t2, t3, and t4 are joined and the outer/inner tables are not specified. Then, the result is joined with t1 and t5, and the outer/inner tables are not specified.
leading(t1 (t2 t3 t4) t5): First, t2, t3, and t4 are joined and the outer/inner tables are not specified. Then, the result is joined with t1, and (t2 t3 t4) is used as the inner table. Finally, the result is joined with t5, and t5 is used as the inner table.
leading((t1 (t2 t3) t4 t5)) leading((t3 t2)): First, t2 and t3 are joined and t2 is used as the inner table. Then, the result is joined with t1, and (t2 t3) is used as the inner table. Finally, the result is joined with t4 and then t5, and the table on the right in each join is used as the inner table.
leading[t1 [t2 t3]] is equivalent to leading((t1 (t2 t3))) leading((t2 t3)).
leading(t1 [t2 t3]) is equivalent to leading(t1 t2 t3) leading((t2 t3)).
leading[@sel$1 t1@sel$1 [t2@sel$2 t3@sel$2]] indicates that t2 and t3 are located in the subquery. After the subquery is promoted, t2 and t3 are joined, and then the join table is joined to t1. Where t2 is a foreign table, t3 is an internal table, t1 is a foreign table. The join table of t2 and t3 is an internal table.
Examples¶
Hint the query plan in Examples as follows:
explain
select /*+ leading((((((store_sales store) promotion) item) customer) ad2) store_returns) leading((store store_sales))*/ i_product_name product_name ...
First, store_sales and store are joined and store_sales is the inner table. Then, The result is joined with promotion, item, customer, ad2, and store_returns in sequence. The optimized plan is as follows:
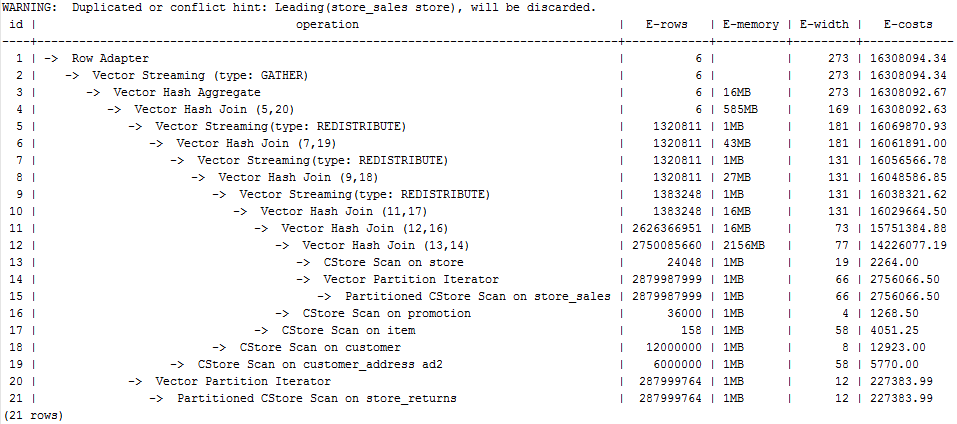
For details about the warning at the top of the plan, see Hint Errors, Conflicts, and Other Warnings.