Query Execution Process¶
The process from receiving SQL statements to the statement execution by the SQL engine is shown in Figure 1 and Table 1. The texts in red are steps where database administrators can optimize queries.
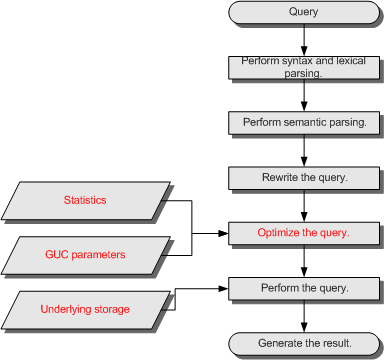
Figure 1 Execution process of query-related SQL statements by the SQL engine¶
Procedure | Description |
|---|---|
| Converts the input SQL statements from the string data type to the formatted structure stmt based on the specified SQL statement rules. |
| Converts the formatted structure obtained from the previous step into objects that can be recognized by the database. |
| Converts the output of the last step into the structure that optimizes the query execution. |
| Determines the execution mode of SQL statements (the execution plan) based on the result obtained from the last step and the internal database statistics. For details about the impact of statistics and GUC parameters on query optimization (execution plan), see Optimizing Queries Using Statistics and Optimizing Queries Using GUC parameters. |
| Executes the SQL statements based on the execution path specified in the last step. Selecting a proper underlying storage mode improves the query execution efficiency. For details, see Optimizing Queries Using the Underlying Storage. |
Optimizing Queries Using Statistics¶
The GaussDB(DWS) optimizer is a typical Cost-based Optimization (CBO). The database uses the CBO to calculate the number of tuples and execution cost for each execution step in every execution plan. This calculation is based on factors such as the number of table tuples, column width, NULL record ratio, and characteristic values (such as distinct, MCV, and HB values) using specific cost calculation methods. The database then selects the execution plan with the lowest cost for overall execution or for returning the first tuple. These characteristic values are the statistics, which is the core for optimizing a query. Accurate statistics helps the optimizer select the most appropriate query plan. Generally, you can collect statistics of a table or that of some columns in a table using ANALYZE. You are advised to periodically execute ANALYZE or execute it immediately after you modified most contents in a table.
Optimizing Queries Using GUC parameters¶
Optimizing queries aims to select an efficient execution mode.
Take the following statement as an example:
SELECT count(1)
FROM customer inner join store_sales on (ss_customer_sk = c_customer_sk);
During execution of customer inner join store_sales, GaussDB(DWS) supports nested loop, merge join, and hash join. The optimizer estimates the result set value and the execution cost under each join mode based on the statistics of the customer and store_sales tables and selects the execution plan that takes the lowest execution cost.
As described in the preceding content, the execution cost is calculated based on certain methods and statistics. If the actual execution cost cannot be accurately estimated, you need to optimize the execution plan by setting the GUC parameters.
Optimizing Queries Using the Underlying Storage¶
GaussDB(DWS) supports row- and column-based tables. The selection of an underlying storage mode strongly depends on specific customer business scenarios. You are advised to use column-store tables for computing service scenarios (mainly involving association and aggregation operations) and row-store tables for service scenarios, such as point queries and massive UPDATE or DELETE executions.
Optimization methods of each storage mode will be described in details in the performance optimization chapter.
Optimizing Queries by Rewriting SQL Statements¶
Besides the preceding methods that improve the performance of the execution plan generated by the SQL engine, database administrators can also enhance SQL statement performance by rewriting SQL statements while retaining the original service logic based on the execution mechanism of the database and abundant practical experience.
This requires that the system administrators know the customer business well and have professional knowledge of SQL statements.