Stream Operation Hints¶
Function¶
Specifies the stream method, which can be broadcast, redistribute, or specifying the distribution key for Agg redistribution.
Note
Specifies the hint for the distribution column during the Agg process. This parameter is supported only by clusters of version 8.1.3.100 or later.
Syntax¶
[no] broadcast | redistribute([@block_name] table_list) | redistribute ([@block_name] (*) (columns))
Parameter Description¶
no indicates that the hinted stream method is not used. When the hint is specified for the distribution columns in the Agg redistribution, no is invalid.
block_name indicates the block name of the statement block. For details, see block_name.
table_list specifies the tables to be joined. For details, see Parameter Description.
When hints are specified for distribution columns, the asterisk (*) is fixed and the table name cannot be specified.
columns specifies one or more columns in the GROUP BY clause. When there are no GROUP BY clauses, it can specify the columns in the DISTINCT clause.
Note
The specified distribution column must be specified using the column sequence number or column name in group by or distinct. The columns in count(distinct) can only be specified using column names.
For a multi-layer query, you can specify the distribution column hint at each layer. The hint takes effect only at the corresponding layer.
The column specified in count(distinct) takes effect only for two-level hashagg plans. Otherwise, the specified distribution column is invalid.
If the optimizer finds that redistribution is not required after estimation, the specified distribution column is invalid.
Tips¶
Generally, the optimizer selects a group of non-skew distribution keys for data redistribution based on statistics. If the default distribution keys have data skew, you can manually specify the distribution columns to avoid data skew.
When selecting a distribution key, select a group of columns with high distinct values as the distribution key based on data distribution features. In this way, data can be evenly distributed to each DN after redistribution.
After writing hints, you can run explain verbose to print the execution plan and check whether the specified distribution key is valid. If the specified distribution key is invalid, a warning is displayed.
Example¶
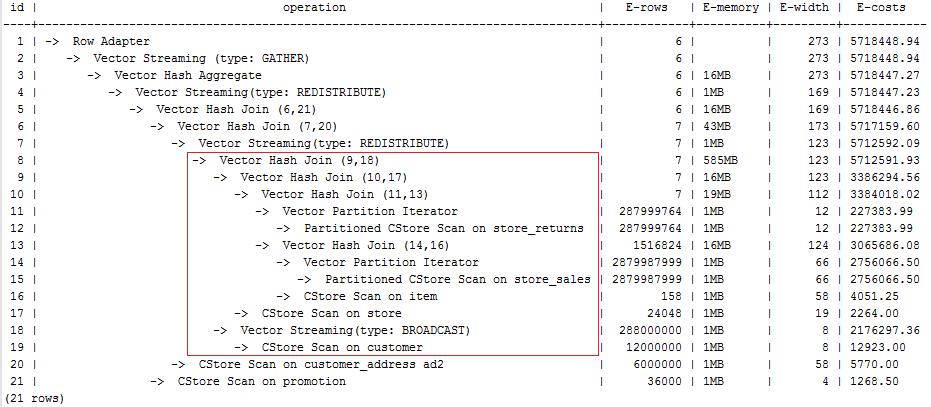
Hint the query plan in Examples as follows:
explain select /*+ no redistribute(store_sales store_returns item store) leading(((store_sales store_returns item store) customer)) */ i_product_name product_name ...
In the original plan, the join result of store_sales, store_returns, item, and store is redistributed before it is joined with customer. After the hinting, the redistribution is disabled and the join order is retained. The optimized plan is as follows:
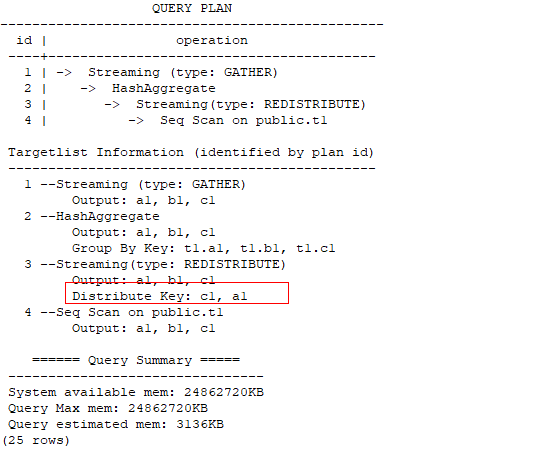
Specifies the distribution columns for Agg redistribution.
explain (verbose on, costs off, nodes off) select /*+ redistribute ((*) (2 3)) */ a1, b1, c1, count(c1) from t1 group by a1, b1, c1 having count(c1) > 10 and sum(d1) > 100
In the following example, the last two columns of the specified GROUP BY columns are used as distribution keys.
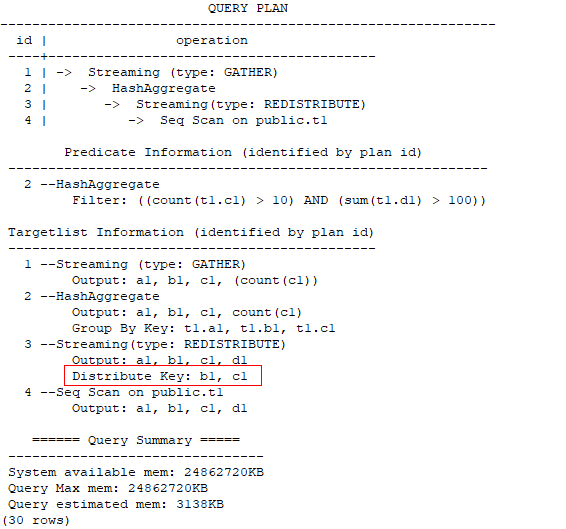
If the statement does not contain the GROUP BY clause, specify the distinct column as the distribution columns.
explain (verbose on, costs off, nodes off) select /*+ redistribute ((*) (3 1)) */ distinct a1, b1, c1 from t1;