Plan Hint Cases¶
This section takes the statements in TPC-DS (Q24) as an example to describe how to optimize an execution plan by using hints in 1000X+24DN environments. For example:
select avg(netpaid) from
(select c_last_name
,c_first_name
,s_store_name
,ca_state
,s_state
,i_color
,i_current_price
,i_manager_id
,i_units
,i_size
,sum(ss_sales_price) netpaid
from store_sales
,store_returns
,store
,item
,customer
,customer_address
where ss_ticket_number = sr_ticket_number
and ss_item_sk = sr_item_sk
and ss_customer_sk = c_customer_sk
and ss_item_sk = i_item_sk
and ss_store_sk = s_store_sk
and c_birth_country = upper(ca_country)
and s_zip = ca_zip
and s_market_id=7
group by c_last_name
,c_first_name
,s_store_name
,ca_state
,s_state
,i_color
,i_current_price
,i_manager_id
,i_units
,i_size);
The original plan of this statement is as follows and the statement execution takes 110s:
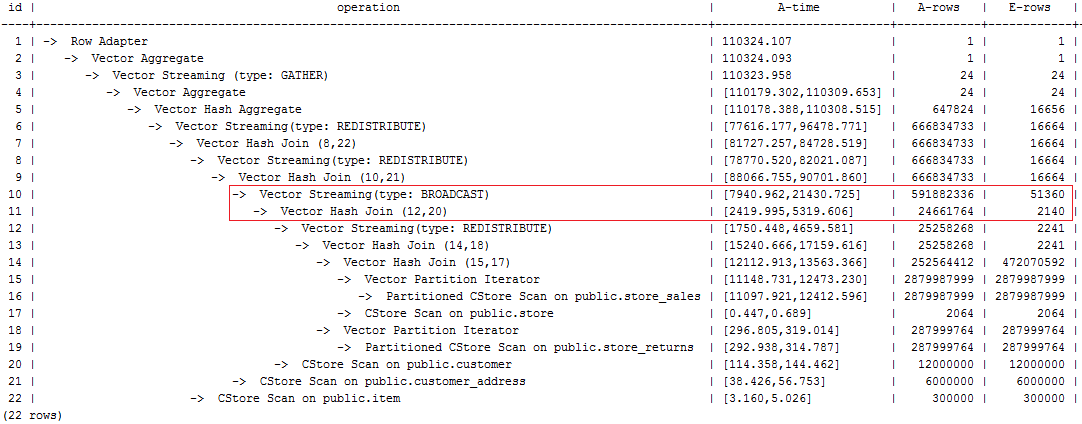
Figure 1 Statement Initial Plan¶
In this plan, the performance of the layer-10 broadcast is poor because the estimation result generated at layer 11 is 2140 rows, which is much less than the actual number of rows. The inaccurate estimation is mainly caused by the underestimated number of rows in layer-13 hash join. In this layer, store_sales and store_returns are joined (based on the ss_ticket_number and ss_item_sk columns in store_sales and the sr_ticket_number and sr_item_sk columns in store_returns) but the multi-column correlation is not considered.
After the rows hint is used for optimization, the plan is as follows and the statement execution takes 318s:
select avg(netpaid) from (select /*+rows(store_sales store_returns * 11270)*/ c_last_name ...
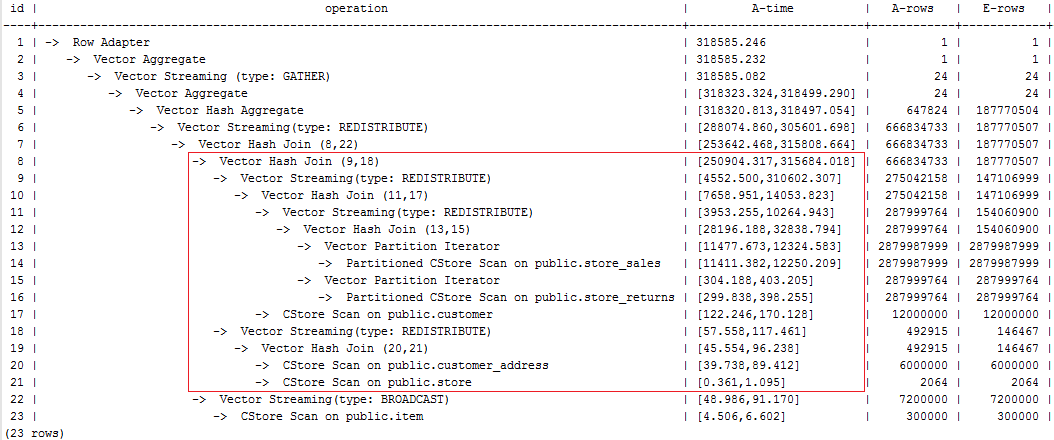
Figure 2 Using rows hints for optimization¶
The execution takes a longer time because layer-9 redistribute is slow. Considering that data skew does not occur at layer-9 redistribute, the slow redistribution is caused by the slow layer-8 hashjoin due to data skew at layer-18 redistribute.
Data skew occurs because customer_address has a few different values in its two join keys. Therefore, plan customer_address as the last one to be joined. After the hint is used for optimization, the plan is as follows and the statement execution takes 116s:
select avg(netpaid) from (select /*+rows(store_sales store_returns *11270) leading((store_sales store_returns store item customer) customer_address)*/ c_last_name ...
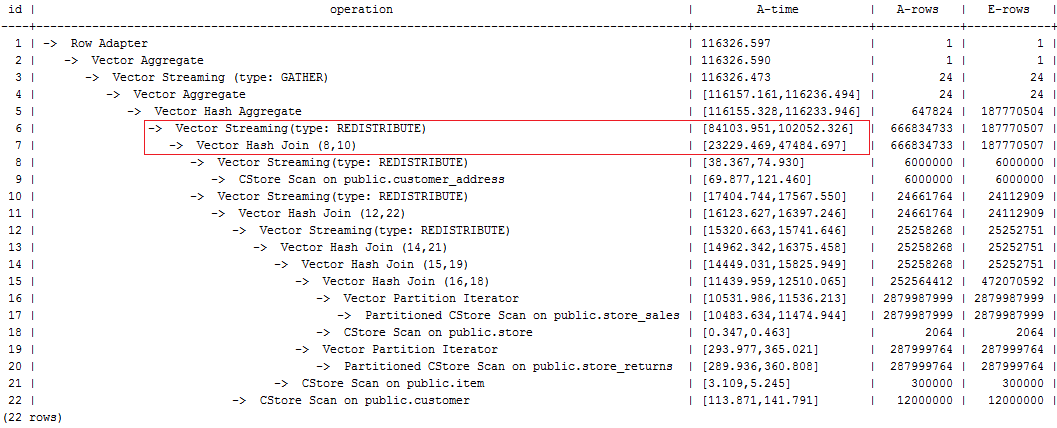
Figure 3 Hint optimization¶
Most of the time is spent on layer-6 redistribute. The plan needs to be further optimized.
The last layer redistribute contains skew. Therefore, it takes a long time. To avoid the data skew, plan the item table as the last one to be joined because the number of rows is not reduced after item is joined. After the hint is used for optimization, the plan is as follows and the statement execution takes 120s:
select avg(netpaid) from (select /*+rows(store_sales store_returns *11270) leading((customer_address (store_sales store_returns store customer) item)) c_last_name ...
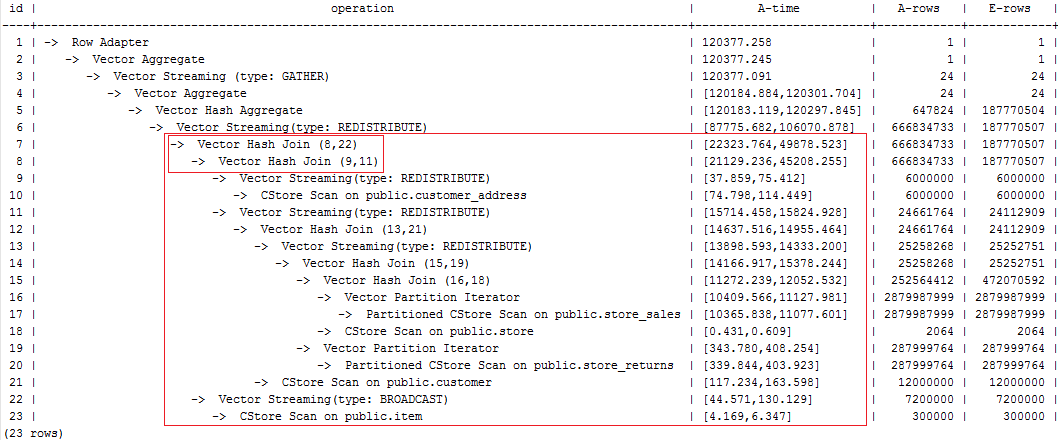
Figure 4 Modifying hints and executing statements¶
Data skew occurs after the join of item and customer_address because item is broadcasted at layer-22. As a result, layer-6 redistribute is still slow.
Add a hint to disable broadcast for item or add a redistribute hint for the join result of item and customer_address. After the hint is used for optimization, the plan is as follows and the statement execution takes 105s:
select avg(netpaid) from (select /*+rows(store_sales store_returns *11270) leading((customer_address (store_sales store_returns store customer) item)) no broadcast(item)*/ c_last_name ...
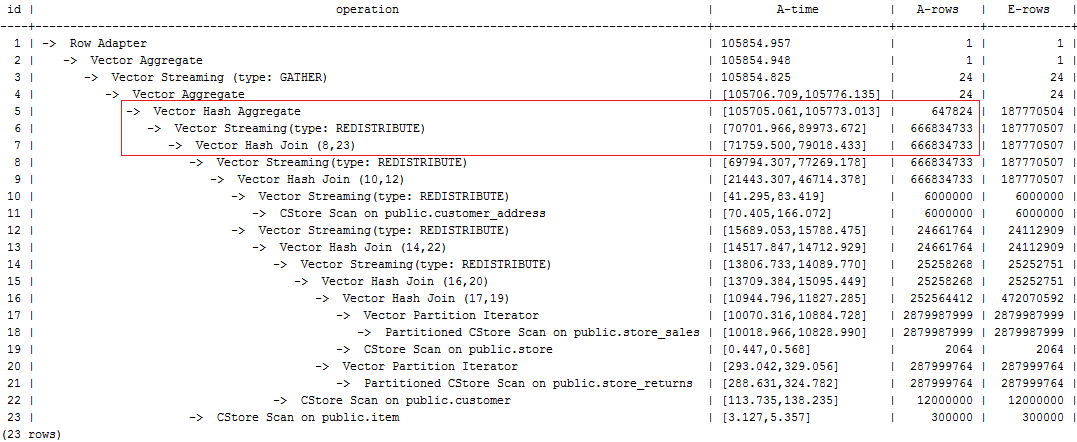
Figure 5 Execution plan¶
The last layer uses single-layer Agg and the number of rows is greatly reduced. Set best_agg_plan to 3 and change the single-layer Agg to a double-layer Agg. The plan is as follows and the statement execution takes 94s. The optimization ends.
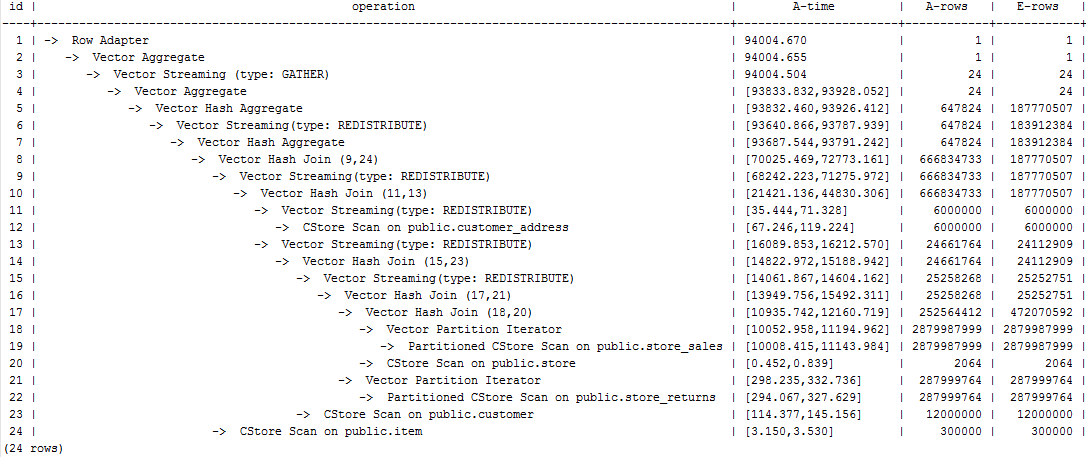
Figure 6 Final optimization plan¶
If the query performance deteriorates due to statistics changes, you can use hints to optimize the query plan. Take TPCH-Q17 as an example. The query performance deteriorates after the value of default_statistics_target is changed from the default one to -2 for statistics collection.
If default_statistics_target is set to the default value 100, the plan is as follows.

Figure 7 Default statistics¶
If default_statistics_target is set to -2, the plan is as follows.
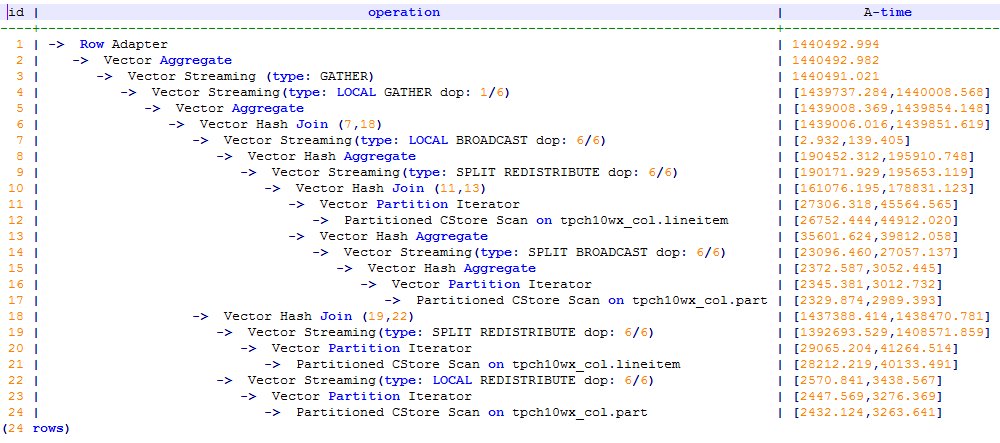
Figure 8 Changes in statistics¶
After the analysis, the cause is that the stream type is changed from BroadCast to Redistribute during the join of the lineitem and part tables. You can use a hint to change the stream type back to BroadCast. For example:
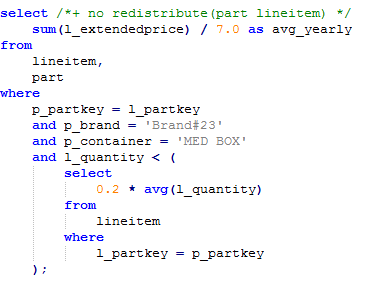
Figure 9 Statements¶