Modifying Database Parameters¶
After a cluster is created, you can modify the cluster's database parameters as required. On the GaussDB(DWS) console, you can configure common database parameters. For details, see Modifying Parameters. You can also view the parameter modification history. For details, see Viewing Parameter Change History. You can run SQL commands to view or set other database parameters. For details, see Setting Configuration Parameters in the Data Warehouse Service Database Development Guide.
Prerequisites¶
You can modify parameters only when no task is running in the cluster.
Modifying Parameters¶
Log in to the GaussDB(DWS) console.
In the navigation pane on the left, choose Clusters > Dedicated Clusters.
In the cluster list, find the target cluster and click the cluster name. The Cluster Information page is displayed.
Click the Parameters tab and modify the parameter values. Then click Save.
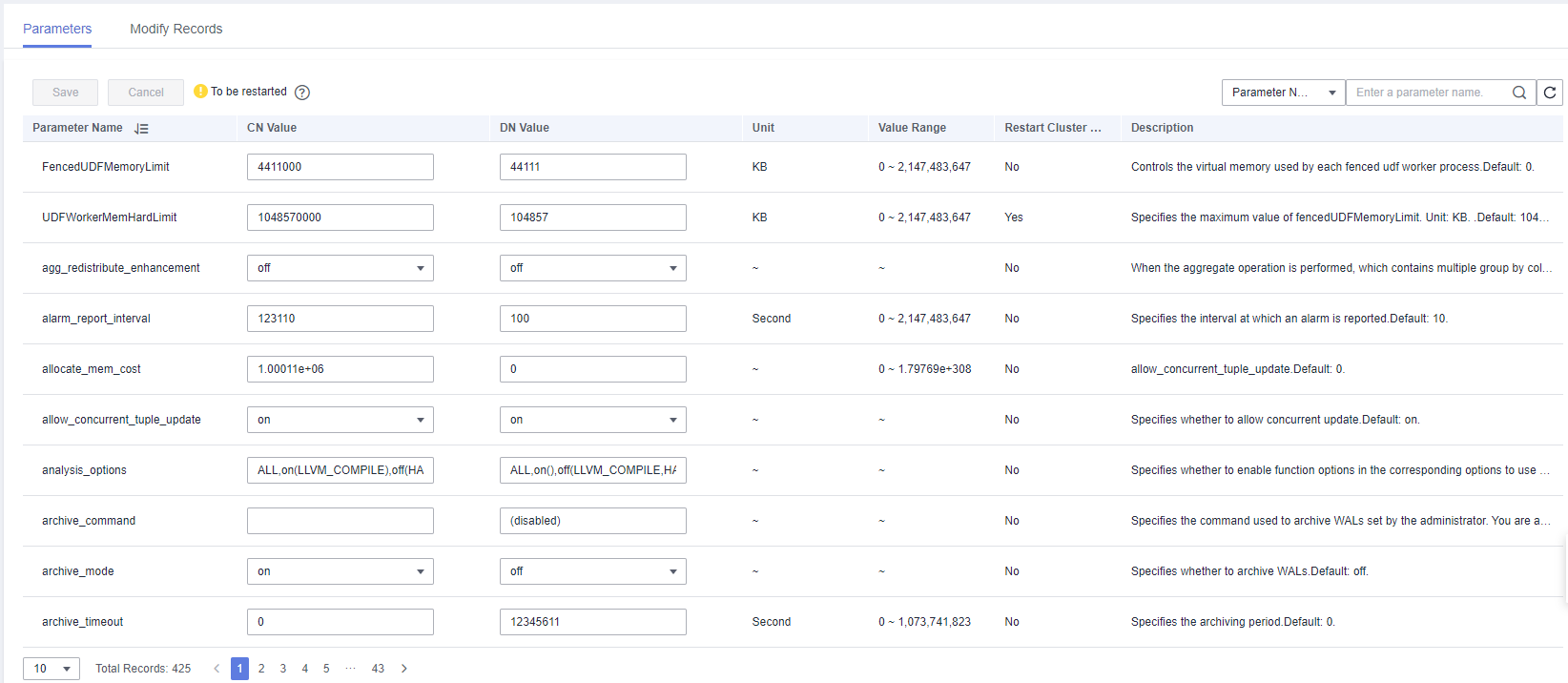
In the Modification Preview dialog box, confirm the modifications and click Save.
You can determine whether you need to restart the cluster after parameter modification based on the Restart Cluster column.

Note
If cluster restart is not required for a parameter, the parameter modification takes effect immediately.
If cluster restart is required for parameter modifications to take effect, the new parameter values will be displayed on the page after the modification, but will not take effect until the cluster is restarted. Before a restart, the cluster status is To be restarted, and some O&M operations are disabled.
Viewing Parameter Change History¶
Perform the following steps to view the parameter modification history and check whether the modifications have taken effect:
Procedure
Log in to the GaussDB(DWS) console.
In the navigation pane on the left, choose Clusters > Dedicated Clusters.
In the cluster list, find the target cluster and click the cluster name. The Cluster Information page is displayed.
Click the Modify Records tab.
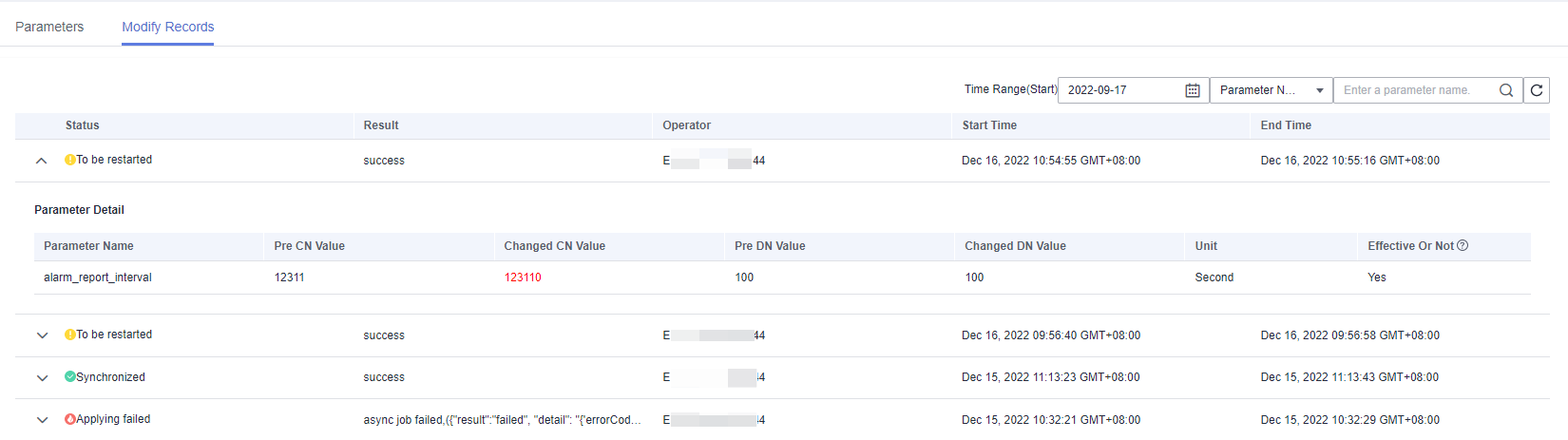
Note
If a parameter can take effect immediately after modification, its status will change to Synchronized after you modify it.
If a parameter can take effect only after a cluster restart, its status will change to To be restarted after you modify it. You can click the expansion icon on the left to view the parameters that have not taken effect. After the cluster is restarted, the status of the record will change to Synchronized.
By default, only the change history within a specified period is displayed. To check the entire change history of a parameter, search for it in the search box in the upper right corner.
Parameter Description¶
There are a large number of database parameters. You can search for and view the parameters on the Parameter Modification page. For details, see Modifying Parameters. The default values of the parameters are for reference only. For more information, see "Setting GUC Parameters".