Flink Basic Principles¶
Overview¶
Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing. Flink features stream processing and is a top open source stream processing engine in the industry.
Flink provides high-concurrency pipeline data processing, millisecond-level latency, and high reliability, making it extremely suitable for low-latency data processing.
Figure 1 shows the technology stack of Flink.
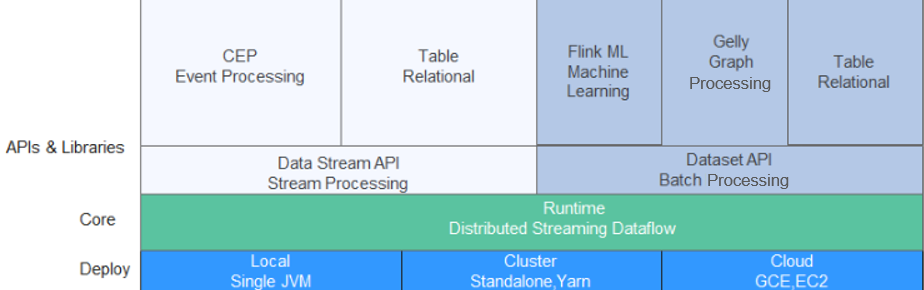
Figure 1 Technology stack of Flink¶
Flink provides the following features in the current version:
DataStream
Checkpoint
Window
Job Pipeline
Configuration Table
Other features are inherited from the open source community and are not enhanced.
Flink Architecture¶
Figure 2 shows the Flink architecture.
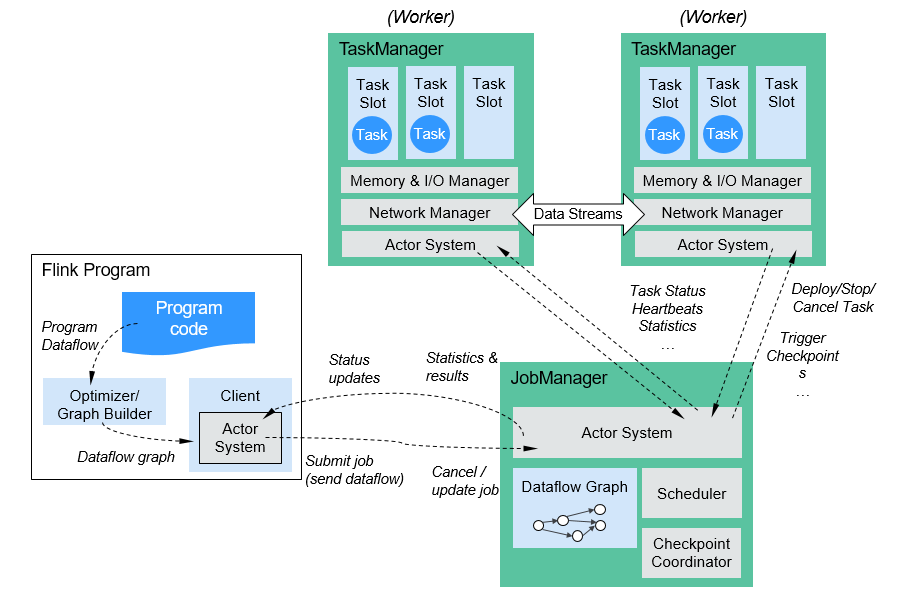
Figure 2 Flink architecture¶
As shown in the above figure, the entire Flink system consists of three parts:
Client
Flink client is used to submit jobs (streaming jobs) to Flink.
TaskManager
TaskManager is a service execution node of Flink. It executes specific tasks. A Flink system can have multiple TaskManagers. These TaskManagers are equivalent to each other.
JobManager
JobManager is a management node of Flink. It manages all TaskManagers and schedules tasks submitted by users to specific TaskManagers. In high-availability (HA) mode, multiple JobManagers are deployed. Among these JobManagers, one is selected as the active JobManager, and the others are standby.
Flink Principles¶
Stream & Transformation & Operator
A Flink program consists of two building blocks: stream and transformation.
Conceptually, a stream is a (potentially never-ending) flow of data records, and a transformation is an operation that takes one or more streams as input, and produces one or more output streams as a result.
When a Flink program is executed, it is mapped to a streaming dataflow. A streaming dataflow consists of a group of streams and transformation operators. Each dataflow starts with one or more source operators and ends in one or more sink operators. A dataflow resembles a directed acyclic graph (DAG).
Figure 3 shows the streaming dataflow to which a Flink program is mapped.
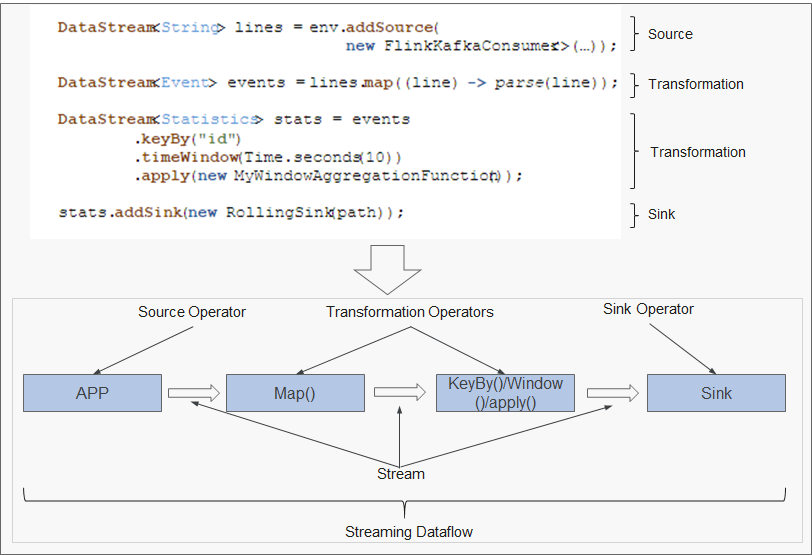
Figure 3 Example of Flink DataStream¶
As shown in Figure 3, FlinkKafkaConsumer is a source operator; Map, KeyBy, TimeWindow, and Apply are transformation operators; RollingSink is a sink operator.
Pipeline Dataflow
Applications in Flink can be executed in parallel or distributed modes. A stream can be divided into one or more stream partitions, and an operator can be divided into multiple operator subtasks.
The executor of streams and operators are automatically optimized based on the density of upstream and downstream operators.
Operators with low density cannot be optimized. Each operator subtask is separately executed in different threads. The number of operator subtasks is the parallelism of that particular operator. The parallelism (the total number of partitions) of a stream is that of its producing operator. Different operators of the same program may have different levels of parallelism, as shown in Figure 4.
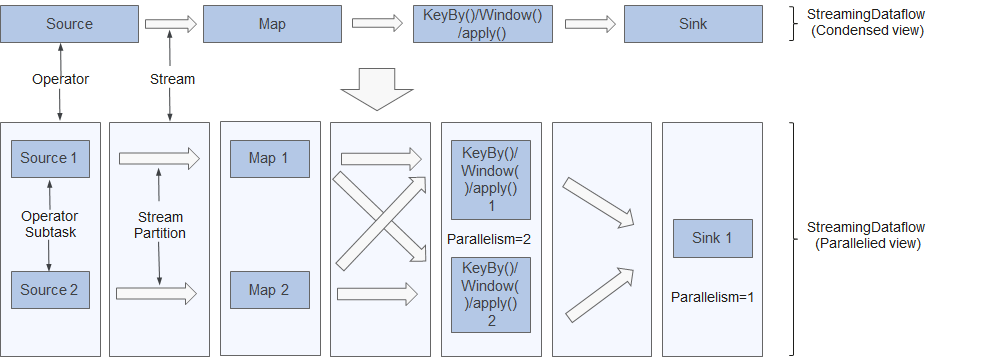
Figure 4 Operator¶
Operators with high density can be optimized. Flink chains operator subtasks together into a task, that is, an operator chain. Each operator chain is executed by one thread on TaskManager, as shown in Figure 5.
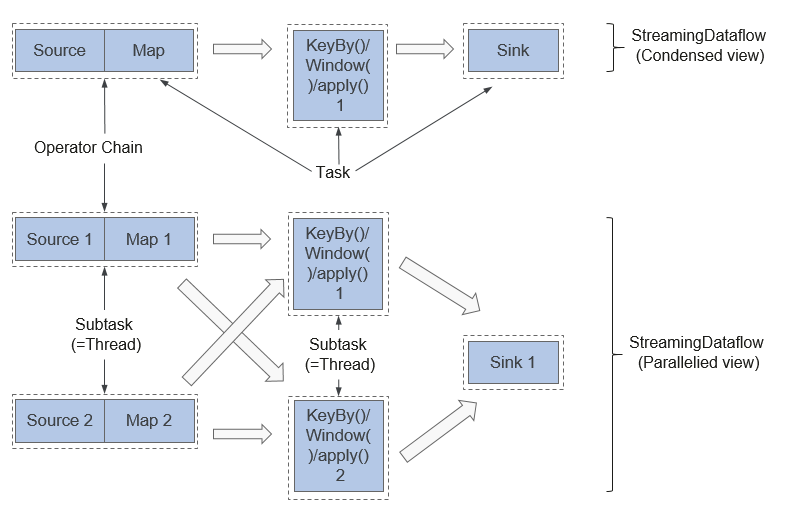
Figure 5 Operator chain¶
In the upper part of Figure 5, the condensed Source and Map operators are chained into an Operator Chain, that is, a larger operator. The Operator Chain, KeyBy, and Sink all represent an operator respectively and are connected with each other through streams. Each operator corresponds to one task during the running. Namely, there are three tasks in the upper part.
In the lower part of Figure 5, each task, except Sink, is paralleled into two subtasks. The parallelism of the Sink operator is one.
Key Features¶
Stream processing
The real-time stream processing engine features high throughput, high performance, and low latency, which can provide processing capability within milliseconds.
Various status management
The stream processing application needs to store the received events or intermediate result in a certain period of time for subsequent access and processing at a certain time point. Flink provides diverse features for status management, including:
Multiple basic status types: Flink provides various states for data structures, such as ValueState, ListState, and MapState. Users can select the most efficient and suitable status type based on the service model.
Rich State Backend: State Backend manages the status of applications and performs Checkpoint operations as required. Flink provides different State Backends. State can be stored in the memory or RocksDB, and supports the asynchronous and incremental Checkpoint mechanism.
Exactly-once state consistency: The Checkpoint and fault recovery capabilities of Flink ensure that the application status of tasks is consistent before and after a fault occurs. Flink supports transactional output for some specific storage devices. In this way, exactly-once output can be ensured even when a fault occurs.
Various time semantics
Time is an important part of stream processing applications. For real-time stream processing applications, operations such as window aggregation, detection, and matching based on time semantics are very common. Flink provides various time semantics.
Event-time: The timestamp provided by the event is used for calculation, making it easier to process the events that arrive at a random sequence or arrive late.
Watermark: Flink introduces the concept of Watermark to measure the development of event time. Watermark also provides flexible assurance for balancing processing latency and data integrity. When processing event streams with Watermark, Flink provides multiple processing options if data arrives after the calculation, for example, redirecting data (side output) or updating the calculation result.
Processing-time and Ingestion-time are supported.
Highly flexible streaming window: Flink supports the time window, count window, session window, and data-driven customized window. You can customize the triggering conditions to implement the complex streaming calculation mode.
Fault tolerance mechanism
In a distributed system, if a single task or node breaks down or is faulty, the entire task may fail. Flink provides a task-level fault tolerance mechanism, which ensures that user data is not lost when an exception occurs in a task and can be automatically restored.
Checkpoint: Flink implements fault tolerance based on checkpoint. Users can customize the checkpoint policy for the entire task. When a task fails, the task can be restored to the status of the latest checkpoint and data after the snapshot is resent from the data source.
Savepoint: A savepoint is a consistent snapshot of application status. The savepoint mechanism is similar to that of checkpoint. However, the savepoint mechanism needs to be manually triggered. The savepoint mechanism ensures that the status information of the current stream application is not lost during task upgrade or migration, facilitating task suspension and recovery at any time point.
Flink SQL
Table APIs and SQL use Apache Calcite to parse, verify, and optimize queries. Table APIs and SQL can be seamlessly integrated with DataStream and DataSet APIs, and support user-defined scalar functions, aggregation functions, and table value functions. The definition of applications such as data analysis and ETL is simplified. The following code example shows how to use Flink SQL statements to define a counting application that records session times.
SELECT userId, COUNT(*) FROM clicks GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
CEP in SQL
Flink allows users to represent complex event processing (CEP) query results in SQL for pattern matching and evaluate event streams on Flink.
CEP SQL is implemented through the MATCH_RECOGNIZE SQL syntax. The MATCH_RECOGNIZE clause is supported by Oracle SQL since Oracle Database 12c and is used to indicate event pattern matching in SQL. The following is an example of CEP SQL:
SELECT T.aid, T.bid, T.cid FROM MyTable MATCH_RECOGNIZE ( PARTITION BY userid ORDER BY proctime MEASURES A.id AS aid, B.id AS bid, C.id AS cid PATTERN (A B C) DEFINE A AS name = 'a', B AS name = 'b', C AS name = 'c' ) AS T