Presto¶
Presto is an open source SQL query engine for running interactive analytic queries against data sources of all sizes. It applies to massive structured/semi-structured data analysis, massive multi-dimensional data aggregation/report, ETL, ad-hoc queries, and more scenarios.
Presto allows querying data where it lives, including HDFS, Hive, HBase, Cassandra, relational databases or even proprietary data stores. A Presto query can combine different data sources to perform data analysis across the data sources.
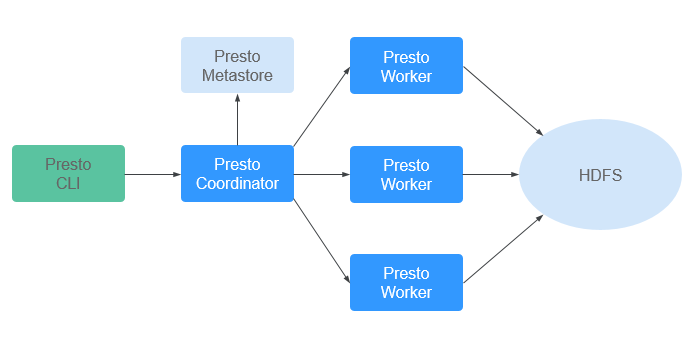
Figure 1 Presto architecture¶
Presto runs in a cluster in distributed mode and contains one coordinator and multiple worker processes. Query requests are submitted from clients (for example, CLI) to the coordinator. The coordinator parses SQL statements, generates execution plans, and distributes the plans to multiple worker processes for execution.
For details about Presto, visit https://prestodb.github.io/ or https://prestosql.io/.
Multiple Presto Instances¶
MRS supports the installation of multiple Presto instances for a large-scale cluster by default. That is, multiple Worker instances, such as Worker1, Worker2, and Worker3, are installed on a Core/Task node. Multiple Worker instances interact with the Coordinator to execute computing tasks, greatly improving node resource utilization and computing efficiency.
Presto multi-instance applies only to the Arm architecture. Currently, a single node supports a maximum of four instances.
For more Presto deployment information, see https://prestodb.io/docs/current/installation/deployment.html or https://trino.io/docs/current/installation/deployment.html.