Training Job Failed Due to OOM¶
Symptom¶
If a training job failed due to out of memory (OOM), possible symptoms were as follows:
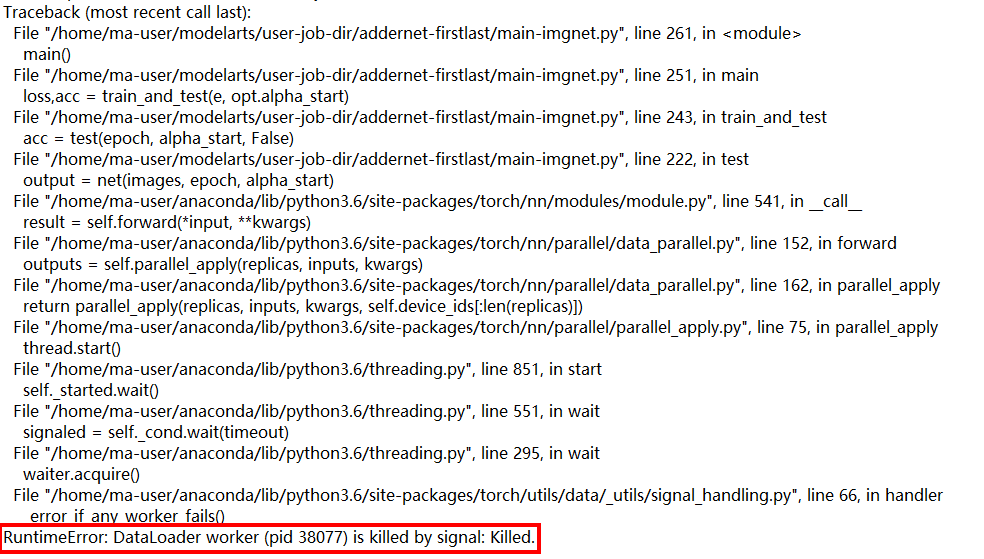

Possible Causes¶
The possible causes are as follows:
GPU memory is insufficient.
OOM occurred on certain nodes. This issue is typically caused by the node fault.
Solution¶
Modify hyperparameter settings to release unnecessary tensors.
Modify network parameters, such as batch_size, hide_layer, and cell_nums.
Release unnecessary tensors.
del tmp_tensor torch.cuda.empty_cache()
Use the local PyCharm to remotely connect to the notebook for debugging.
If the fault persists, submit a service ticket to locate the fault or even isolate the affected node.
Summary and Suggestions¶
Before creating a training job, use the ModelArts development environment to debug the training code to maximally eliminate errors in code migration.