Training Fault Tolerance Check¶
During model training, a training failure may occur due to a hardware fault. For hardware faults, ModelArts provides fault tolerance check to isolate faulty nodes to improve user experience in training.
The fault tolerance check involves environment pre-check and periodic hardware check. If any fault is detected during either of the checks, ModelArts automatically isolates the faulty hardware and issues the training job again. In distributed training, the fault tolerance check will be performed on all compute nodes used by the training job.
The following shows four failure scenarios, among which the failure in scenario 4 is not caused by a hardware fault. You can enable fault tolerance in the other three scenarios to automatically resume the training job.
Scenario 1: The environment pre-check fails, and the hardware is faulty. Then, ModelArts automatically isolates all faulty nodes and issues the training job again.
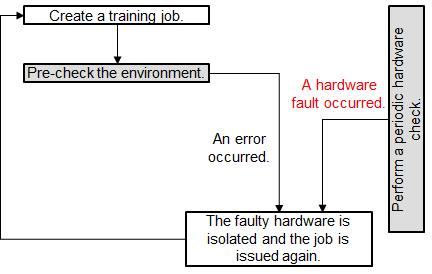
Figure 1 Pre-check failure and hardware fault¶
Scenario 2: The environment pre-check fails but the hardware is functional. Then, ModelArts automatically isolates all faulty nodes and issues the training job again.
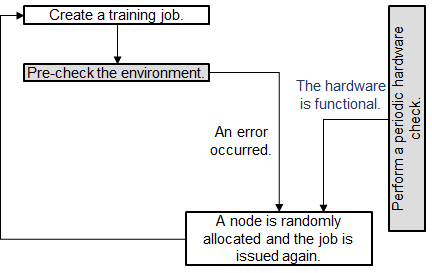
Figure 2 Pre-check failure but functional hardware¶
Scenario 3: The environment pre-check is successful and the user service starts. A hardware fault occurs and the user service exits unexpectedly. Then, ModelArts automatically isolates all faulty nodes and issues the training job again.
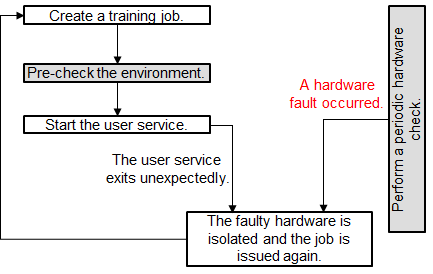
Figure 3 Service failure and hardware fault¶
Scenario 4: The environment pre-check is successful and the user service starts. The hardware is functional. A fault occurs in the user service, the training job ends in the failure state.
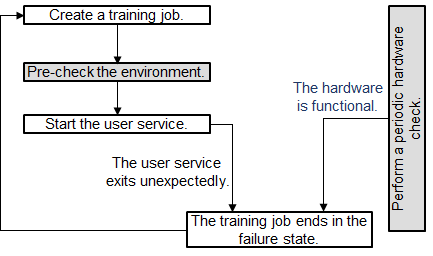
Figure 4 Service failure and functional hardware¶
After the faulty node is isolated, ModelArts creates a training job on new compute nodes. If the resources provided by the resource pool are limited, the re-issued training job will be queued with the highest priority. If the waiting time exceeds 30 minutes, the training job will automatically exit. This indicates that the resources are so limited that the training job cannot start. In this case, buy a dedicated resource pool to obtain dedicated resources.
If you use a dedicated resource pool to create a training job, the faulty nodes identified during the fault tolerance check will be removed. The system automatically adds healthy compute nodes to the dedicated resource pool. (This function is coming soon.)
More details of a fault tolerance check:
After the environment pre-check is successful, any hardware fault will interrupt the user service. Add the reload ckpt code logic to the training so that the pre-trained model saved before the training is interrupted can be obtained. For details, see Resumable Training and Incremental Training.
Enabling Fault Tolerance Check¶
To enable fault tolerance check, enable auto restart when creating a training job.
Configure fault tolerance check on the ModelArts management console:
Enable Auto Restart on the ModelArts management console. Auto Restart is disabled by default, indicating that the job will not be re-issued and the environment pre-check will not be enabled. After Auto Restart is enabled, the number of restart retries ranges from 1 to 3.
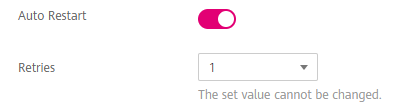
Figure 5 Auto Restart¶
Configure fault tolerance check using an API:
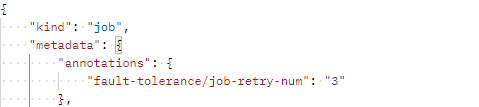
Enable auto restart upon a fault using an API. When creating a training job, configure the fault-tolerance/job-retry-num field in annotations of the metadata field.
If the fault-tolerance/job-retry-num field is added, auto restart is enabled. The value can be an integer ranging from 1 to 3. specifying the maximum number of times that a job can be re-issued. If this hyperparameter is not specified, the default value 0 is used, indicating that the job will not be re-issued and the environment pre-check will not be enabled.
Check Items and Conditions¶
Check Item | Item (Log Keyword) | Execution Condition | Requirements for a Check |
|---|---|---|---|
Domain name detection | dns | None | The domain names of the volcano containers in the .host file in /etc/volcano are successfully resolved. |
Disk size - Container root directory | disk-size root | None | The directory is greater than 32 GB. |
Disk size - /dev/shm | disk-size shm | None | The directory is greater than 1 GB. |
Disk size - /cache | disk-size cache | None | The directory is greater than 32 GB. |
ulimit check | ulimit | An IB network is used. |
|
GPU check | gpu-check | GPU and the v2 training engine are used. | GPUs are detected. |
Effect of a Fault Tolerance Check¶
If the fault tolerance check is passed, the logs of the check items will be recorded, indicating that the check items are successful. You can search for the keyword item in the log file. A fault tolerance check minimizes reported runtime faults.

If a fault tolerance check fails, check failure logs will be recorded. You can search for the keyword item in the log file to view the failure information.
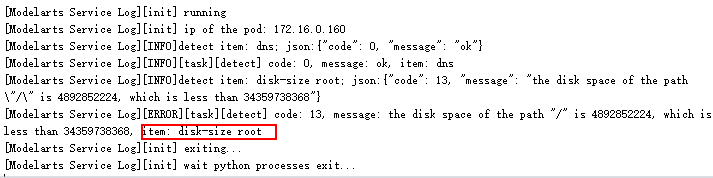
If the number of job restarts does not reach the specified time, the job will be automatically issued again. You can search for keywords error,exiting to obtain the logs recording a restarted job that ends with a failure.
Using reload ckpt to Resume an Interrupted Training¶
With fault tolerance enabled, if a training job is restarted due to a hardware fault, you can obtain the pre-trained model in the code to restore the training to the state before the restart. To do so, add reload ckpt to the code. For details, see Resumable Training and Incremental Training.