Model Deployment¶
ModelArts is capable of managing models and services. This allows mainstream framework images and models from multiple vendors to be managed in a unified manner.
Generally, AI model deployment and large-scale implementation are complex.
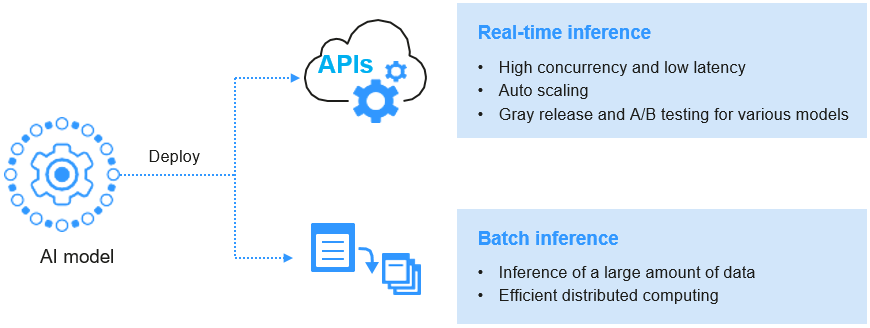
Figure 1 Process of deploying a model¶
The real-time inference service features high concurrency, low latency, and elastic scaling, and supports multi-model gray release and A/B testing.