Built-in Object Detection Mode¶
Input¶
This is a built-in input and output mode for object detection. The models using this mode are identified as object detection models. The prediction request path is /, the request protocol is HTTP, the request method is POST, Content-Type is multipart/form-data, key is images, and type is file. Before selecting this mode, ensure that your model can process the input data whose key is images.
Output¶
The inference result is returned in JSON format. For details about the fields, see Table 1.
Field | Type | Description |
|---|---|---|
detection_classes | String array | Types of detected objects, for example, ["bicycle","bus"] |
detection_boxes | Float array | Coordinates of the bounding box, in the format of |
detection_scores | Float array | Confidence scores of detected objects, which are used to measure the detection accuracy |
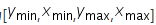
The JSON Schema of the inference result is as follows:
{
"type": "object",
"properties": {
"detection_classes": {
"items": {
"type": "string"
},
"type": "array"
},
"detection_boxes": {
"items": {
"minItems": 4,
"items": {
"type": "number"
},
"type": "array",
"maxItems": 4
},
"type": "array"
},
"detection_scores": {
"items": {
"type": "string"
},
"type": "array"
}
}
}
Sample Request¶
In this mode, input an image to be processed in the inference request. The inference result is returned in JSON format. The following are examples:
Performing prediction on the console
On the Prediction tab page of the service details page, upload an image and click Predict to obtain the prediction result.
Using Postman to call a RESTful API for prediction
After a model is deployed as a service, you can obtain the API URL on the Usage Guides tab page of the service details page.
On the Headers tab page, set Content-Type to multipart/form-data and X-Auth-Token to the actual token obtained.
On the Body tab page, set the request body. Set key to images, select File, select the image to be processed, and click send to send your prediction request.