Introduction to Inference¶
After an AI model is developed, you can use it to create a model and quickly deploy the application as an inference service. The AI inference capabilities can be integrated into your IT platform by calling APIs.
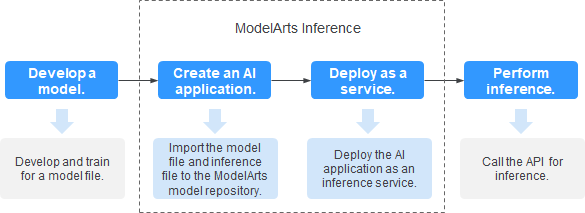
Figure 1 Inference¶
Develop a model: Models can be developed in ModelArts or your local development environment. A locally developed model must be uploaded to OBS.
Create a model: Import the model file and inference file to the ModelArts model repository and manage them by version. Use these files to build an executable model.
Deploy as a service: Deploy the model as a container instance in the resource pool and register inference APIs that can be accessed externally.
Perform inference: Add the function of calling the inference APIs to your application to integrate AI inference into the service process.
Deploying a Model as a Service¶
After a model is created, you can deploy it as a service on the Deploy page. ModelArts supports the following deployment types:
Deploy a model as a web service with real-time test UI and monitoring supported.
Deploy a model as a batch service that performs inference on batch data and automatically stops after data processing is complete.