Loader Basic Principles¶
Loader is developed based on the open source Sqoop component. It is used to exchange data and files between MRS and relational databases and file systems. Loader can import data from relational databases or file servers to the HDFS and HBase components, or export data from HDFS and HBase to relational databases or file servers.
A Loader model consists of Loader Client and Loader Server, as shown in Figure 1.
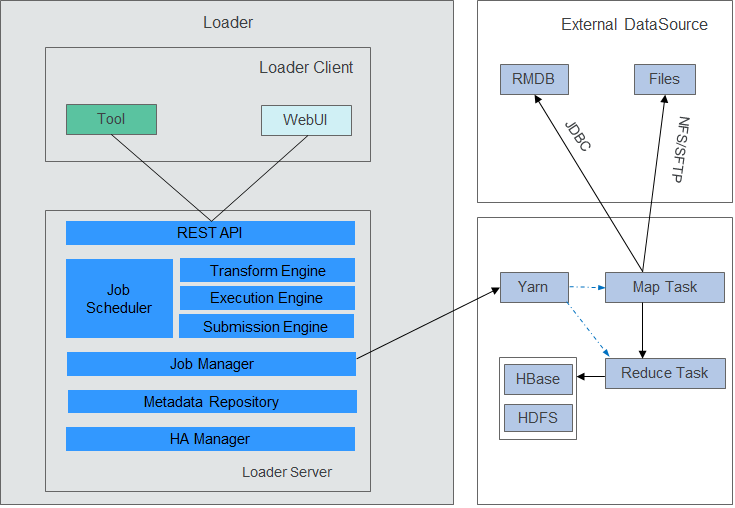
Figure 1 Loader model¶
Table 1 describes the functions of each module shown in the preceding figure.
Module | Description |
|---|---|
Loader Client | Loader client. It provides two interfaces: web UI and CLI. |
Loader Server | Loader server. It processes operation requests sent from the client, manages connectors and metadata, submits MapReduce jobs, and monitors MapReduce job status. |
REST API | It provides a Representational State Transfer (RESTful) APIs (HTTP + JSON) to process the operation requests sent from the client. |
Job Scheduler | Simple job scheduler. It periodically executes Loader jobs. |
Transform Engine | Data transformation engine. It supports field combination, string cutting, and string reverse. |
Execution Engine | Loader job execution engine. It executes Loader jobs in MapReduce manner. |
Submission Engine | Loader job submission engine. It submits Loader jobs to MapReduce. |
Job Manager | It manages Loader jobs, including creating, querying, updating, deleting, activating, deactivating, starting, and stopping jobs. |
Metadata Repository | Metadata repository. It stores and manages data about Loader connectors, transformation procedures, and jobs. |
HA Manager | It manages the active/standby status of Loader Server processes. The Loader Server has two nodes that are deployed in active/standby mode. |
Loader imports or exports jobs in parallel using MapReduce jobs. Some job import or export may involve only the Map operations, while some may involve both Map and Reduce operations.
Loader implements fault tolerance using MapReduce. Jobs can be rescheduled upon a job execution failure.
Importing data to HBase
When the Map operation is performed for MapReduce jobs, Loader obtains data from an external data source.
When a Reduce operation is performed for a MapReduce job, Loader enables the same number of Reduce tasks based on the number of Regions. The Reduce tasks receive data from Map tasks, generate HFiles by Region, and store the HFiles in a temporary directory of HDFS.
When a MapReduce job is submitted, Loader migrates HFiles from the temporary directory to the HBase directory.
Importing Data to HDFS
When a Map operation is performed for a MapReduce job, Loader obtains data from an external data source and exports the data to a temporary directory (named export directory-ldtmp).
When a MapReduce job is submitted, Loader migrates data from the temporary directory to the output directory.
Exporting data to a relational database
When a Map operation is performed for a MapReduce job, Loader obtains data from HDFS or HBase and inserts the data to a temporary table (Staging Table) through the Java DataBase Connectivity (JDBC) API.
When a MapReduce job is submitted, Loader migrates data from the temporary table to a formal table.
Exporting data to a file system
When a Map operation is performed for a MapReduce job, Loader obtains data from HDFS or HBase and writes the data to a temporary directory of the file server.
When a MapReduce job is submitted, Loader migrates data from the temporary directory to a formal directory.
For details about the Loader architecture and principles, see https://sqoop.apache.org/docs/1.99.3/index.html.