Kafka Basic Principles¶
Kafka is an open source, distributed, partitioned, and replicated commit log service. Kafka is publish-subscribe messaging, rethought as a distributed commit log. It provides features similar to Java Message Service (JMS) but another design. It features message endurance, high throughput, distributed methods, multi-client support, and real time. It applies to both online and offline message consumption, such as regular message collection, website activeness tracking, aggregation of statistical system operation data (monitoring data), and log collection. These scenarios engage large amounts of data collection for Internet services.
Kafka Structure¶
Producers publish data to topics, and consumers subscribe to the topics and consume messages. A broker is a server in a Kafka cluster. For each topic, the Kafka cluster maintains partitions for scalability, parallelism, and fault tolerance. Each partition is an ordered, immutable sequence of messages that is continually appended to - a commit log. Each message in a partition is assigned a sequential ID, which is called offset.
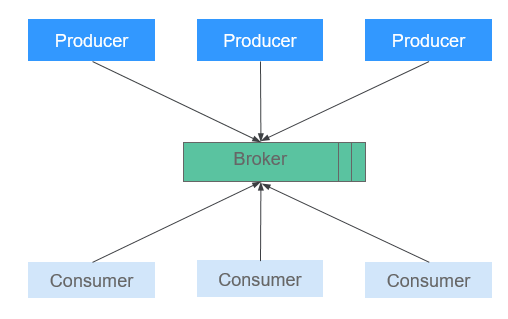
Figure 1 Kafka architecture¶
Name | Description |
|---|---|
Broker | A broker is a server in a Kafka cluster. |
Topic | A topic is a category or feed name to which messages are published. A topic can be divided into multiple partitions, which can act as a parallel unit. |
Partition | A partition is an ordered, immutable sequence of messages that is continually appended to - a commit log. The messages in the partitions are each assigned a sequential ID number called the offset that uniquely identifies each message within the partition. |
Producer | Producers publish messages to a Kafka topic. |
Consumer | Consumers subscribe to topics and process the feed of published messages. |
Figure 2 shows the relationships between modules.
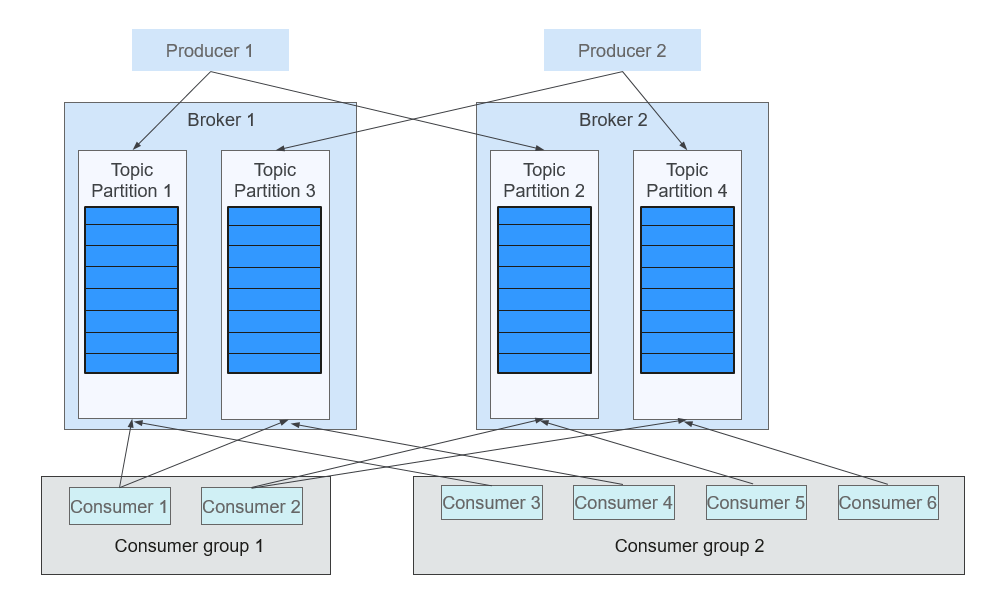
Figure 2 Relationships between Kafka modules¶
Consumers label themselves with a consumer group name, and each message published to a topic is delivered to one consumer instance within each subscribing consumer group. If all the consumer instances belong to the same consumer group, loads are evenly distributed among the consumers. As shown in the preceding figure, Consumer1 and Consumer2 work in load-sharing mode; Consumer3, Consumer4, Consumer5, and Consumer6 work in load-sharing mode. If all the consumer instances belong to different consumer groups, messages are broadcast to all consumers. As shown in the preceding figure, the messages in Topic 1 are broadcast to all consumers in Consumer Group1 and Consumer Group2.
For details about Kafka architecture and principles, see https://kafka.apache.org/24/documentation.html.
Principle¶
Message Reliability
When a Kafka broker receives a message, it stores the message on a disk persistently. Each partition of a topic has multiple replicas stored on different broker nodes. If one node is faulty, the replicas on other nodes can be used.
High Throughput
Kafka provides high throughput in the following ways:
Messages are written into disks instead of being cached in the memory, fully utilizing the sequential read and write performance of disks.
The use of zero-copy eliminates I/O operations.
Data is sent in batches, improving network utilization.
Each topic is divided in to multiple partitions, which increases concurrent processing. Concurrent read and write operations can be performed between multiple producers and consumers. Producers send messages to specified partitions based on the algorithm used.
Message Subscribe-Notify Mechanism
Consumers subscribe to interested topics and consume data in pull mode. Consumers can choose the consumption mode, such as batch consumption, repeated consumption, and consumption from the end, and control the message pulling speed based on actual situation. Consumers need to maintain the consumption records by themselves.
Scalability
When broker nodes are added to expand the Kafka cluster capacity, the newly added brokers register with ZooKeeper. After the registration is successful, procedures and consumers can sense the change in a timely manner and make related adjustment.
Open Source Features¶
Reliability
Message processing methods such as At-Least Once, At-Most Once, and Exactly Once are provided. The message processing status is maintained by consumers. Kafka needs to work with the application layer to implement Exactly Once.
High throughput
High throughput is provided for message publishing and subscription.
Persistence
Messages are stored on disks and can be used for batch consumption and real-time application programs. Data persistence and replication prevent data loss.
Distribution
A distributed system is easy to be expanded externally. All producers, brokers, and consumers support the deployment of multiple distributed clusters. Systems can be scaled without stopping the running of software or shutting down the machines.