Hive Basic Principles¶
Hive is a data warehouse infrastructure built on Hadoop. It provides a series of tools that can be used to extract, transform, and load (ETL) data. Hive is a mechanism that can store, query, and analyze mass data stored on Hadoop. Hive defines simple SQL-like query language, which is known as HiveQL. It allows a user familiar with SQL to query data. Hive data computing depends on MapReduce, Spark, and Tez.
The new execution engine Tez is used to replace the original MapReduce, greatly improving performance. Tez can convert multiple dependent jobs into one job, so only once HDFS write is required and fewer transit nodes are needed, greatly improving the performance of DAG jobs.
Hive provides the following functions:
Analyzes massive structured data and summarizes analysis results.
Allows complex MapReduce jobs to be compiled in SQL languages.
Supports flexible data storage formats, including JavaScript object notation (JSON), comma separated values (CSV), TextFile, RCFile, SequenceFile, and ORC (Optimized Row Columnar).
Hive system structure:
User interface: Three user interfaces are available, that is, CLI, Client, and WUI. CLI is the most frequently-used user interface. A Hive transcript is started when CLI is started. Client refers to a Hive client, and a client user connects to the Hive Server. When entering the client mode, you need to specify the node where the Hive Server resides and start the Hive Server on this node. The web UI is used to access Hive through a browser. MRS can access Hive only in client mode.
Metadata storage: Hive stores metadata into databases, for example, MySQL and Derby. Metadata in Hive includes a table name, table columns and partitions and their properties, table properties (indicating whether a table is an external table), and the directory where table data is stored.
Hive Framework¶
Hive is a single-instance service process that provides services by translating HQL into related MapReduce jobs or HDFS operations. Figure 1 shows how Hive is connected to other components.
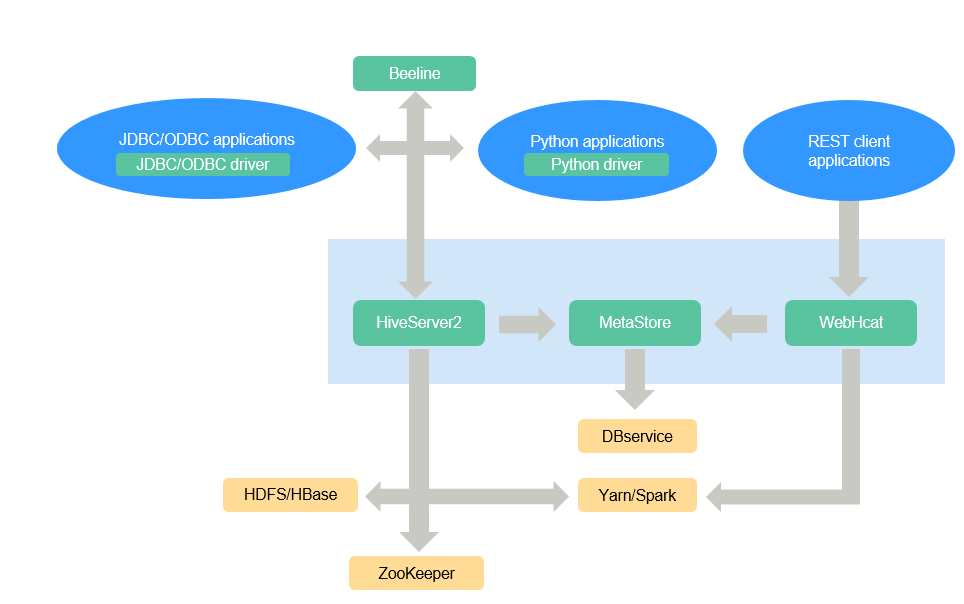
Figure 1 Hive framework¶
Module | Description |
|---|---|
HiveServer | Multiple HiveServers can be deployed in a cluster to share loads. HiveServer provides Hive database services externally, translates HQL statements into related YARN tasks or HDFS operations to complete data extraction, conversion, and analysis. |
MetaStore |
|
WebHCat | Multiple WebHCats can be deployed in a cluster to share loads. WebHCat provides REST APIs and runs the Hive commands through the REST APIs to submit MapReduce jobs. |
Hive client | Hive client includes the human-machine command-line interface (CLI) Beeline, JDBC drive for JDBC applications, Python driver for Python applications, and HCatalog JAR files for MapReduce. |
ZooKeeper cluster | As a temporary node, ZooKeeper records the IP address list of each HiveServer instance. The client driver connects to ZooKeeper to obtain the list and selects corresponding HiveServer instances based on the routing mechanism. |
HDFS/HBase cluster | The HDFS cluster stores the Hive table data. |
MapReduce/YARN cluster | Provides distributed computing services. Most Hive data operations rely on MapReduce. The main function of HiveServer is to translate HQL statements into MapReduce jobs to process massive data. |
HCatalog is built on Hive Metastore and incorporates the DDL capability of Hive. HCatalog is also a Hadoop-based table and storage management layer that enables convenient data read/write on tables of HDFS by using different data processing tools such MapReduce. Besides, HCatalog also provides read/write APIs for these tools and uses a Hive CLI to publish commands for defining data and querying metadata. After encapsulating these commands, WebHCat Server can provide RESTful APIs, as shown in Figure 2.
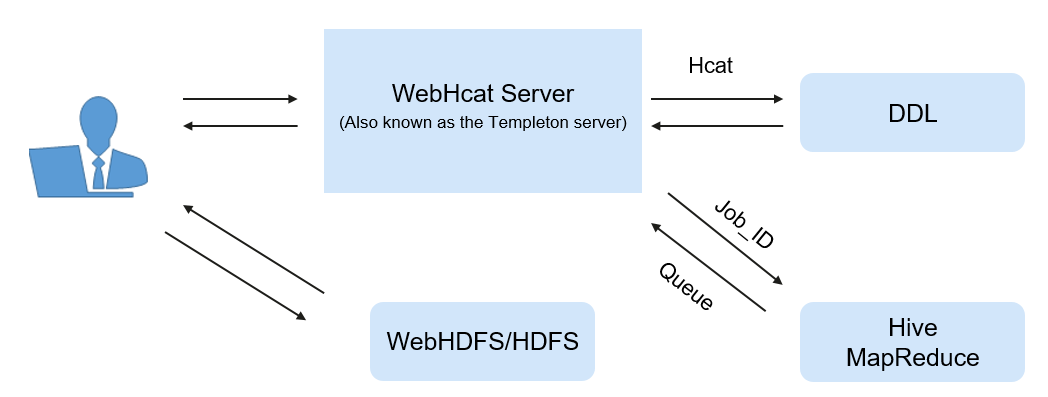
Figure 2 WebHCat logical architecture¶
Principles¶
Hive functions as a data warehouse based on HDFS and MapReduce architecture and translates HQL statements into MapReduce jobs or HDFS operations. For details about Hive and HQL, see HiveQL Language Manual.
Figure 3 shows the Hive structure.
Metastore: reads, writes, and updates metadata such as tables, columns, and partitions. Its lower layer is relational databases.
Driver: manages the lifecycle of HiveQL execution and participates in the entire Hive job execution.
Compiler: translates HQL statements into a series of interdependent Map or Reduce jobs.
Optimizer: is classified into logical optimizer and physical optimizer to optimize HQL execution plans and MapReduce jobs, respectively.
Executor: runs Map or Reduce jobs based on job dependencies.
ThriftServer: functions as the servers of JDBC, provides Thrift APIs, and integrates with Hive and other applications.
Clients: include the WebUI and JDBC APIs and provides APIs for user access.
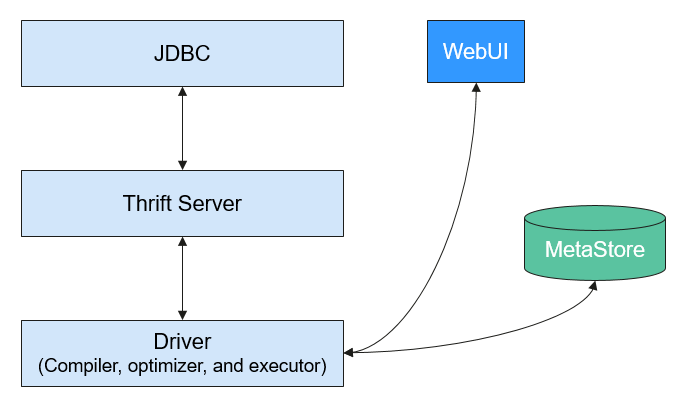
Figure 3 Hive framework¶