Relationship Between HDFS and Other Components¶
Relationship Between HDFS and HBase¶
HDFS is a subproject of Apache Hadoop, which is used as the file storage system for HBase. HBase is located in the structured storage layer. HDFS provides highly reliable support for lower-layer storage of HBase. All the data files of HBase can be stored in the HDFS, except some log files generated by HBase.
Relationship Between HDFS and MapReduce¶
HDFS features high fault tolerance and high throughput, and can be deployed on low-cost hardware for storing data of applications with massive data sets.
MapReduce is a programming model used for parallel computation of large data sets (larger than 1 TB). Data computed by MapReduce comes from multiple data sources, such as Local FileSystem, HDFS, and databases. Most data comes from the HDFS. The high throughput of HDFS can be used to read massive data. After being computed, data can be stored in HDFS.
Relationship Between HDFS and Spark¶
Data computed by Spark comes from multiple data sources, such as local files and HDFS. Most data comes from HDFS which can read data in large scale for parallel computing. After being computed, data can be stored in HDFS.
Spark involves Driver and Executor. Driver schedules tasks and Executor runs tasks.
Figure 1 shows how data is read from a file.
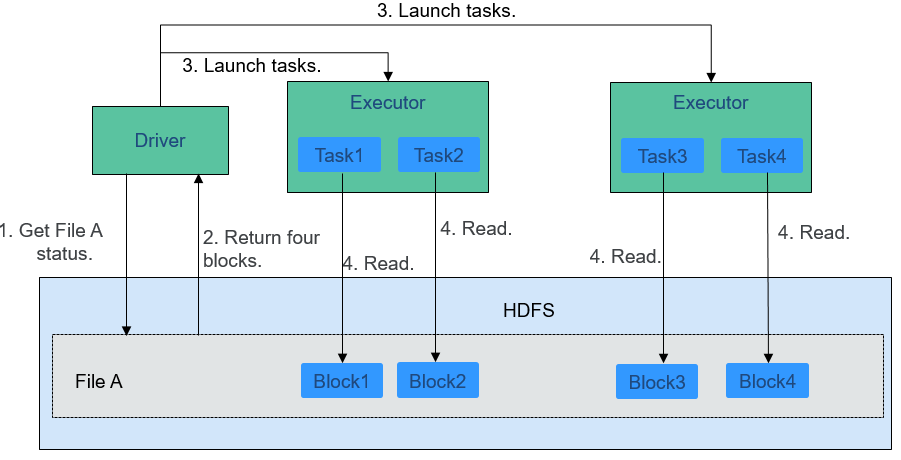
Figure 1 File reading process¶
The file reading process is as follows:
Driver interconnects with HDFS to obtain the information of File A.
The HDFS returns the detailed block information about this file.
Driver sets a parallel degree based on the block data amount, and creates multiple tasks to read the blocks of this file.
Executor runs the tasks and reads the detailed blocks as part of the Resilient Distributed Dataset (RDD).
Figure 2 shows how data is written to a file.
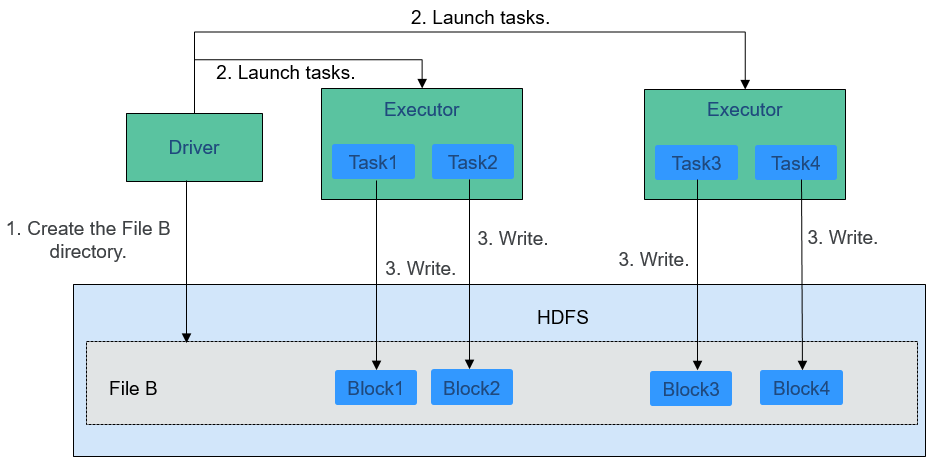
Figure 2 File writing process¶
The file writing process is as follows:
Driver creates a directory where the file is to be written.
Based on the RDD distribution status, the number of tasks related to data writing is computed, and these tasks are sent to Executor.
Executor runs these tasks, and writes the computed RDD data to the directory created in 1.
Relationship Between HDFS and ZooKeeper¶
Figure 3 shows the relationship between ZooKeeper and HDFS.
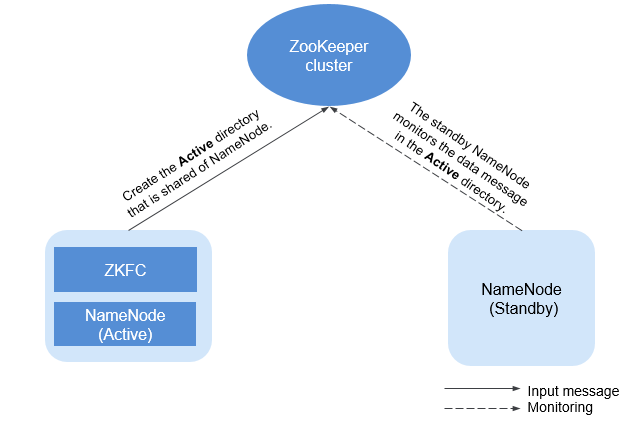
Figure 3 Relationship between ZooKeeper and HDFS¶
As the client of a ZooKeeper cluster, ZKFailoverController (ZKFC) monitors the status of NameNode. ZKFC is deployed only in the node where NameNode resides, and in both the active and standby HDFS NameNodes.
The ZKFC connects to ZooKeeper and saves information such as host names to ZooKeeper under the znode directory /hadoop-ha. NameNode that creates the directory first is considered as the active node, and the other is the standby node. NameNodes read the NameNode information periodically through ZooKeeper.
When the process of the active node ends abnormally, the standby NameNode detects changes in the /hadoop-ha directory through ZooKeeper, and then takes over the service of the active NameNode.