HDFS Enhanced Open Source Features¶
Enhanced Open Source Feature: File Block Colocation¶
In the offline data summary and statistics scenario, Join is a frequently used computing function, and is implemented in MapReduce as follows:
The Map task processes the records in the two table files into Join Key and Value, performs hash partitioning by Join Key, and sends the data to different Reduce tasks for processing.
Reduce tasks read data in the left table recursively in the nested loop mode and traverse each line of the right table. If join key values are identical, join results are output.
The preceding method sharply reduces the performance of the join calculation. Because a large amount of network data transfer is required when the data stored in different nodes is sent from MAP to Reduce, as shown in Figure 1.
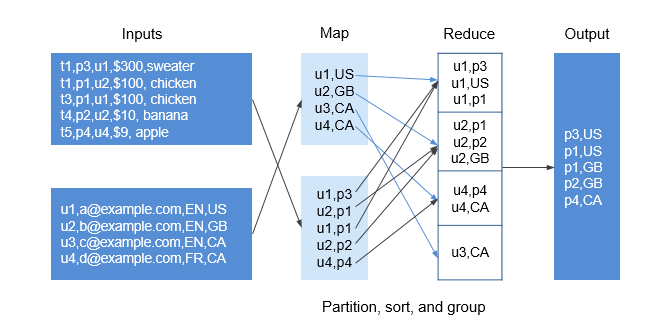
Figure 1 Data transmission in the non-colocation scenario¶
Data tables are stored in physical file system by HDFS block. Therefore, if two to-be-joined blocks are put into the same host accordingly after they are partitioned by join key, you can obtain the results directly from Map join in the local node without any data transfer in the Reduce process of the join calculation. This will greatly improve the performance.
With the identical distribution feature of HDFS data, a same distribution ID is allocated to files, FileA and FileB, on which association and summation calculations need to be performed. In this way, all the blocks are distributed together, and calculation can be performed without retrieving data across nodes, which greatly improves the MapReduce join performance.
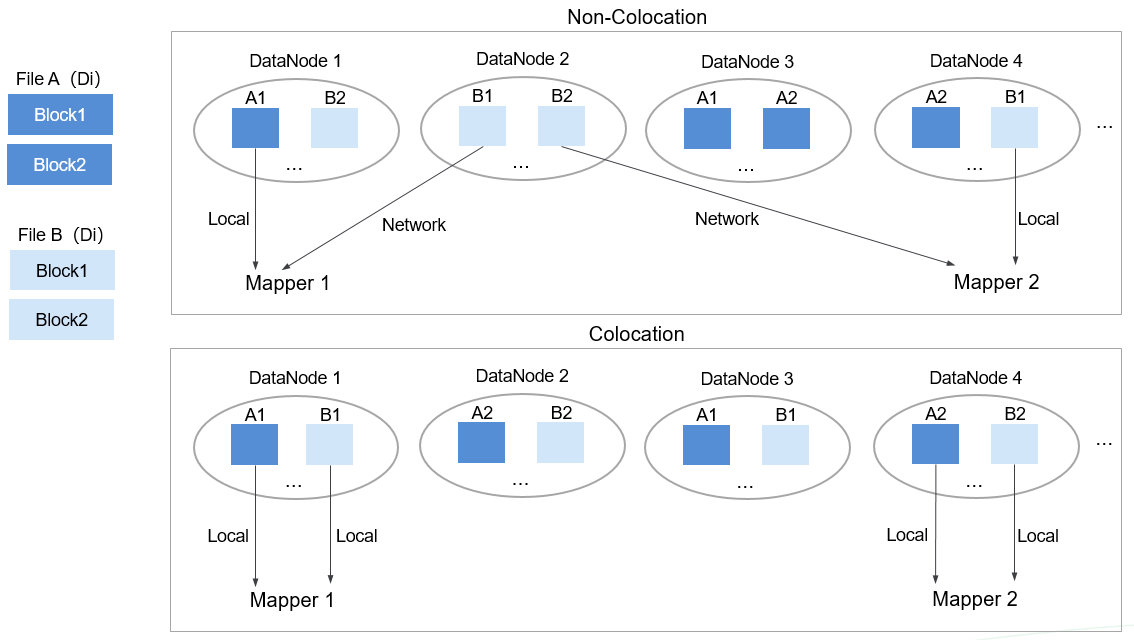
Figure 2 Data block distribution in colocation and non-colocation scenarios¶
Enhanced Open Source Feature: Damaged Hard Disk Volume Configuration¶
In the open source version, if multiple data storage volumes are configured for a DataNode, the DataNode stops providing services by default if one of the volumes is damaged. If the configuration item dfs.datanode.failed.volumes.tolerated is set to specify the number of damaged volumes that are allowed, DataNode continues to provide services when the number of damaged volumes does not exceed the threshold.
The value of dfs.datanode.failed.volumes.tolerated ranges from -1 to the number of disk volumes configured on the DataNode. The default value is -1, as shown in Figure 3.
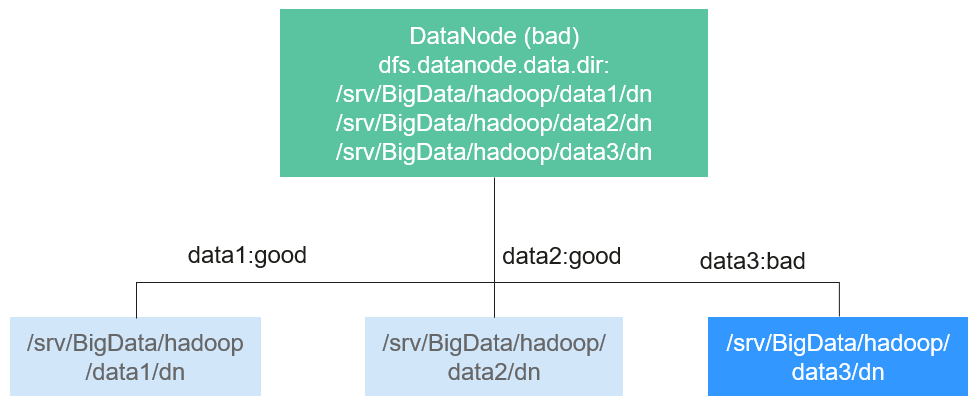
Figure 3 Item being set to 0¶
For example, three data storage volumes are mounted to a DataNode, and dfs.datanode.failed.volumes.tolerated is set to 1. In this case, if one data storage volume of the DataNode is unavailable, this DataNode can still provide services, as shown in Figure 4.
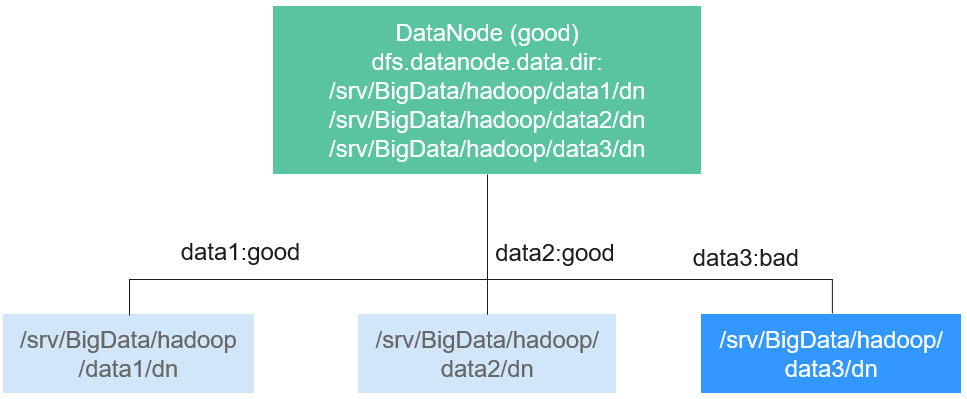
Figure 4 Item being set to 1¶
This native configuration item has some defects. When the number of data storage volumes in each DataNode is inconsistent, you need to configure each DataNode independently instead of generating the unified configuration file for all nodes.
Assume that there are three DataNodes in a cluster. The first node has three data directories, the second node has four, and the third node has five. If you want to ensure that DataNode services are available when only one data directory is available, you need to perform the configuration as shown in Figure 5.
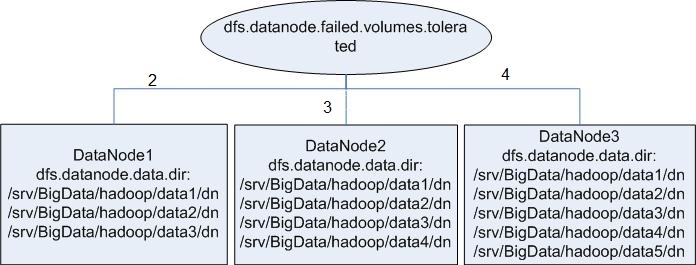
Figure 5 Attribute configuration before being enhanced¶
In self-developed enhanced HDFS, this configuration item is enhanced, with a value -1 added. When this configuration item is set to -1, all DataNodes can provide services as long as one data storage volume in all DataNodes is available.
To resolve the problem in the preceding example, set this configuration to -1, as shown in Figure 6.
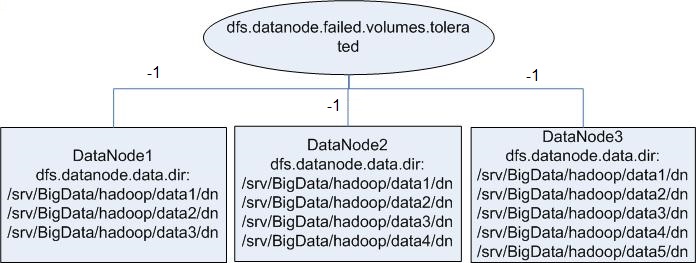
Figure 6 Attribute configuration after being enhanced¶
Enhanced Open Source Feature: HDFS Startup Acceleration¶
In HDFS, when NameNodes start, the metadata file FsImage needs to be loaded. Then, DataNodes will report the data block information after the DataNodes startup. When the data block information reported by DataNodes reaches the preset percentage, NameNodes exits safe mode to complete the startup process. If the number of files stored on the HDFS reaches the million or billion level, the two processes are time-consuming and will lead to a long startup time of the NameNode. Therefore, this version optimizes the process of loading metadata file FsImage.
In the open source HDFS, FsImage stores all types of metadata information. Each type of metadata information (such as file metadata information and folder metadata information) is stored in a section block, respectively. These section blocks are loaded in serial mode during startup. If a large number of files and folders are stored on the HDFS, loading of the two sections is time-consuming, prolonging the HDFS startup time. HDFS NameNode divides each type of metadata by segments and stores the data in multiple sections when generating the FsImage files. When the NameNodes start, sections are loaded in parallel mode. This accelerates the HDFS startup.
Enhanced Open Source Feature: Label-based Block Placement Policies (HDFS Nodelabel)¶
You need to configure the nodes for storing HDFS file data blocks based on data features. You can configure a label expression to an HDFS directory or file and assign one or more labels to a DataNode so that file data blocks can be stored on specified DataNodes. If the label-based data block placement policy is used for selecting DataNodes to store the specified files, the DataNode range is specified based on the label expression. Then proper nodes are selected from the specified range.
You can store the replicas of data blocks to the nodes with different labels accordingly. For example, store two replicas of the data block to the node labeled with L1, and store other replicas of the data block to the nodes labeled with L2.
You can set the policy in case of block placement failure, for example, select a node from all nodes randomly.
Figure 7 gives an example:
Data in /HBase is stored in A, B, and D.
Data in /Spark is stored in A, B, D, E, and F.
Data in /user is stored in C, D, and F.
Data in /user/shl is stored in A, E, and F.
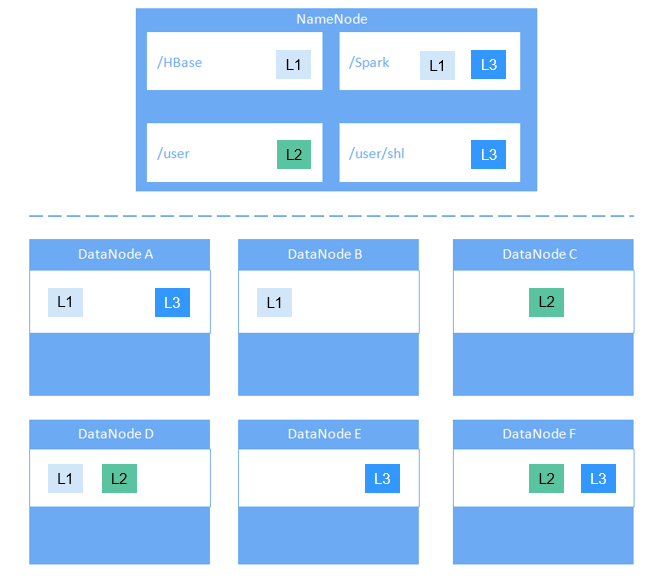
Figure 7 Example of label-based block placement policy¶
Enhanced Open Source Feature: HDFS Load Balance¶
The current read and write policies of HDFS are mainly for local optimization without considering the actual load of nodes or disks. Based on I/O loads of different nodes, the load balance of HDFS ensures that when read and write operations are performed on the HDFS client, the node with low I/O load is selected to perform such operations to balance I/O load and fully utilize the overall throughput of the cluster.
If HDFS Load Balance is enabled during file writing, the NameNode selects a DataNode (in the order of local node, local rack, and remote rack). If the I/O load of the selected node is heavy, the NameNode will choose another DataNode with lighter load.
If HDFS Load Balance is enabled during file reading, an HDFS client sends a request to the NameNode to provide the list of DataNodes that store the block to be read. The NameNode returns a list of DataNodes sorted by distance in the network topology. With the HDFS Load Balance feature, the DataNodes on the list are also sorted by their I/O load. The DataNodes with heavy load are at the bottom of the list.
Enhanced Open Source Feature: HDFS Auto Data Movement¶
Hadoop has been used for batch processing of immense data in a long time. The existing HDFS model is used to fit the needs of batch processing applications very well because such applications focus more on throughput than delay.
However, as Hadoop is increasingly used for upper-layer applications that demand frequent random I/O access such as Hive and HBase, low latency disks such as solid state disk (SSD) are favored in delay-sensitive scenarios. To cater to the trend, HDFS supports a variety of storage types. Users can choose a storage type according to their needs.
Storage policies vary depending on how frequently data is used. For example, if data that is frequently accessed in the HDFS is marked as ALL_SSD or HOT, the data that is accessed several times may be marked as WARM, and data that is rarely accessed (only once or twice access) can be marked as COLD. You can select different data storage policies based on the data access frequency.

However, low latency disks are far more expensive than spinning disks. Data typically sees heavy initial usage with decline in usage over a period of time. Therefore, it can be useful if data that is no longer used is moved out from expensive disks to cheaper ones storage media.
A typical example is storage of detail records. New detail records are imported into SSD because they are frequently queried by upper-layer applications. As access frequency to these detail records declines, they are moved to cheaper storage.
Before automatic data movement is achieved, you have to manually determine by service type whether data is frequently used, manually set a data storage policy, and manually trigger the HDFS Auto Data Movement Tool, as shown in the figure below.
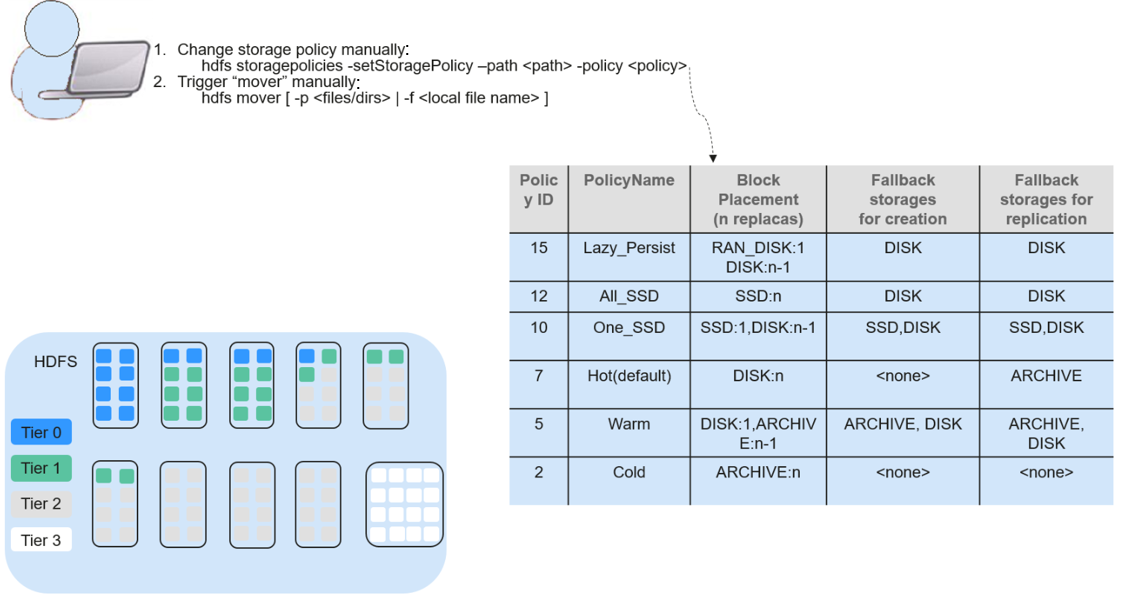
If aged data can be automatically identified and moved to cheaper storage (such as disk/archive), you will see significant cost cuts and data management efficiency improvement.
The HDFS Auto Data Movement Tool is at the core of HDFS Auto Data Movement. It automatically sets a storage policy depending on how frequently data is used. Specifically, functions of the HDFS Auto Data Movement Tool can:
Mark a data storage policy as All_SSD, One_SSD, Hot, Warm, Cold, or FROZEN according to age, access time, and manual data movement rules.
Define rules for distinguishing cold and hot data based on the data age, access time, and manual migration rules.
Define the action to be taken if age-based rules are met.
MARK: the action for identifying whether data is frequently or rarely used based on the age rules and setting a data storage policy. MOVE: the action for invoking the HDFS Auto Data Movement Tool and moving data based on the age rules to identify whether data is frequently or rarely used after you have determined the corresponding storage policy.
MARK: identifies whether data is frequently or rarely used and sets the data storage policy.
MOVE: the action for invoking the HDFS Auto Data Movement Tool and moving data across tiers.
SET_REPL: the action for setting new replica quantity for a file.
MOVE_TO_FOLDER: the action for moving files to a target folder.
DELETE: the action for deleting a file or directory.
SET_NODE_LABEL: the action for setting node labels of a file.
With the HDFS Auto Data Movement feature, you only need to define age based on access time rules. HDFS Auto Data Movement Tool matches data according to age-based rules, sets storage policies, and moves data. In this way, data management efficiency and cluster resource efficiency are improved.