HBase Enhanced Open Source Features¶
HIndex¶
HBase is a distributed storage database of the Key-Value type. Data of a table is sorted in the alphabetic order based on row keys. If you query data based on a specified row key or scan data in the scale of a specified row key, HBase can quickly locate the target data, enhancing the efficiency.
However, in most actual scenarios, you need to query the data of which the column value is XXX. HBase provides the Filter feature to query data with a specific column value. All data is scanned in the order of row keys, and then the data is matched with the specific column value until the required data is found. The Filter feature scans some unnecessary data to obtain the only required data. Therefore, the Filter feature cannot meet the requirements of frequent queries with high performance standards.
HBase HIndex is designed to address these issues. HBase HIndex enables HBase to query data based on specific column values.
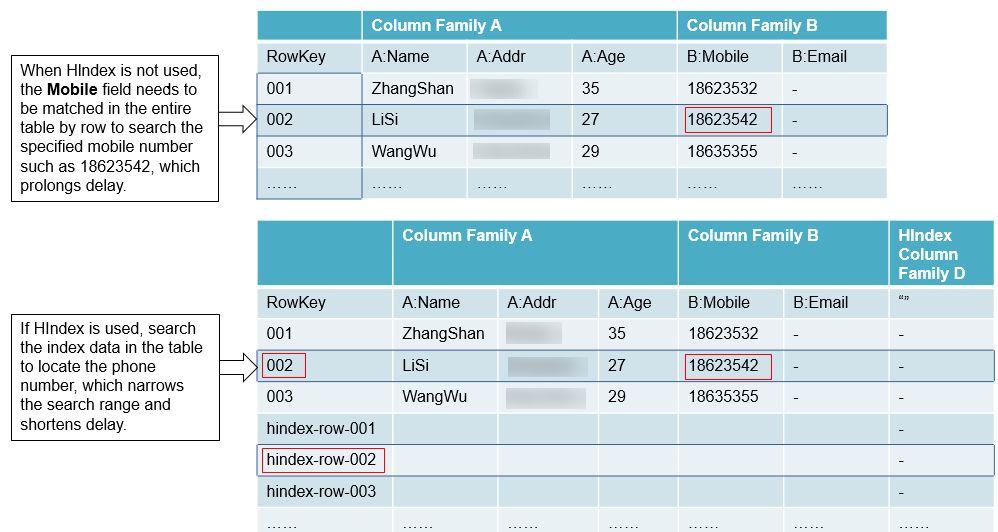
Figure 1 HIndex¶
Rolling upgrade is not supported for index data.
Restrictions of combined indexes:
All columns involved in combined indexes must be entered or deleted in a single mutation. Otherwise, inconsistency will occur.
Index: IDX1=>cf1:[q1->datatype],[q2];cf2:[q2->datatype]
Correct write operations:
Put put = new Put(Bytes.toBytes("row")); put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q1"), Bytes.toBytes("valueA")); put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q2"), Bytes.toBytes("valueB")); put.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q2"), Bytes.toBytes("valueC")); table.put(put);
Incorrect write operations:
Put put1 = new Put(Bytes.toBytes("row")); put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q1"), Bytes.toBytes("valueA")); table.put(put1); Put put2 = new Put(Bytes.toBytes("row")); put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q2"), Bytes.toBytes("valueB")); table.put(put2); Put put3 = new Put(Bytes.toBytes("row")); put3.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q2"), Bytes.toBytes("valueC")); table.put(put3);
The combined conditions-based query is supported only when the combined index column contains filter criteria, or StartRow and StopRow are not specified for some index columns.
Index: IDX1=>cf1:[q1->datatype],[q2];cf2:[q1->datatype]
Correct query operations:
scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',>=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf1','q2',>=,'binary:valueB',true,true) AND SingleColumnValueFilter('cf2','q1',>=,'binary:valueC',true,true) "} scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf1','q2',>=,'binary:valueB',true,true)" } scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',>=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf1','q2',>=,'binary:valueB',true,true) AND SingleColumnValueFilter('cf2','q1',>=,'binary:valueC',true,true)",STARTROW=>'row001',STOPROW=>'row100'}
Incorrect query operations:
scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',>=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf1','q2',>=,'binary:valueB',true,true) AND SingleColumnValueFilter('cf2','q1',>=,'binary:valueC',true,true) AND SingleColumnValueFilter('cf2','q2',>=,'binary:valueD',true,true)"} scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf2','q1',>=,'binary:valueC',true,true)" } scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf2','q2',>=,'binary:valueD',true,true)" } scan 'table', {FILTER=>"SingleColumnValueFilter('cf1','q1',=,'binary:valueA',true,true) AND SingleColumnValueFilter('cf1','q2',>=,'binary:valueB',true,true)" ,STARTROW=>'row001',STOPROW=>'row100' }
Do not explicitly configure any split policy for tables with index data.
Other mutation operations, such as increment and append, are not supported.
Index of the column with maxVersions greater than 1 is not supported.
The data index column in a row cannot be updated.
Index 1: IDX1=>cf1:[q1->datatype],[q2];cf2:[q1->datatype]
Index 2: IDX2=>cf2:[q2->datatype]
Correct update operations:
Put put1 = new Put(Bytes.toBytes("row")); put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q1"), Bytes.toBytes("valueA")); put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q2"), Bytes.toBytes("valueB")); put1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q1"), Bytes.toBytes("valueC")); put1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q2"), Bytes.toBytes("valueD")); table.put(put1); Put put2 = new Put(Bytes.toBytes("row")); put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q3"), Bytes.toBytes("valueE")); put2.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q3"), Bytes.toBytes("valueF")); table.put(put2);
Incorrect update operations:
Put put1 = new Put(Bytes.toBytes("row")); put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q1"), Bytes.toBytes("valueA")); put1.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q2"), Bytes.toBytes("valueB")); put1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q1"), Bytes.toBytes("valueC")); put1.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q2"), Bytes.toBytes("valueD")); table.put(put1); Put put2 = new Put(Bytes.toBytes("row")); put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q1"), Bytes.toBytes("valueA_new")); put2.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("q2"), Bytes.toBytes("valueB_new")); put2.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q1"), Bytes.toBytes("valueC_new")); put2.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("q2"), Bytes.toBytes("valueD_new")); table.put(put2);
The table to which an index is added cannot contain a value greater than 32 KB.
If user data is deleted due to the expiration of the column-level TTL, the corresponding index data is not deleted immediately. It will be deleted in the major compaction operation.
The TTL of the user column family cannot be modified after the index is created.
If the TTL of a column family increases after an index is created, delete the index and re-create one. Otherwise, some generated index data will be deleted before user data is deleted.
If the TTL value of the column family decreases after an index is created, the index data will be deleted after user data is deleted.
The index query does not support the reverse operation, and the query results are disordered.
The index does not support the clone snapshot operation.
The index table must use HIndexWALPlayer to replay logs. WALPlayer cannot be used to replay logs.
hbase org.apache.hadoop.hbase.hindex.mapreduce.HIndexWALPlayer Usage: WALPlayer [options] <wal inputdir> <tables> [<tableMappings>] Read all WAL entries for <tables>. If no tables ("") are specific, all tables are imported. (Careful, even -ROOT- and hbase:meta entries will be imported in that case.) Otherwise <tables> is a comma separated list of tables. The WAL entries can be mapped to new set of tables via <tableMapping>. <tableMapping> is a command separated list of targettables. If specified, each table in <tables> must have a mapping. By default WALPlayer will load data directly into HBase. To generate HFiles for a bulk data load instead, pass the option: -Dwal.bulk.output=/path/for/output (Only one table can be specified, and no mapping is allowed!) Other options: (specify time range to WAL edit to consider) -Dwal.start.time=[date|ms] -Dwal.end.time=[date|ms] For performance also consider the following options: -Dmapreduce.map.speculative=false -Dmapreduce.reduce.speculative=falseWhen the deleteall command is executed for the index table, the performance is low.
The index table does not support HBCK. To use HBCK to repair the index table, delete the index data first.
Multi-point Division¶
When you create tables that are pre-divided by region in HBase, you may not know the data distribution trend so the division by region may be inappropriate. After the system runs for a period, regions need to be divided again to achieve better performance. Only empty regions can be divided.
The region division function delivered with HBase divides regions only when they reach the threshold. This is called "single point division".
To achieve better performance when regions are divided based on user requirements, multi-point division is developed, which is also called "dynamic division". That is, an empty region is pre-divided into multiple regions to prevent performance deterioration caused by insufficient region space.
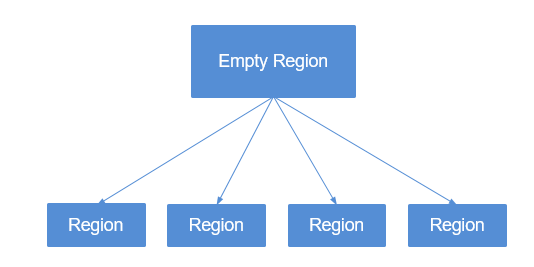
Figure 2 Multi-point division¶
Connection Limitation¶
Too many sessions mean that too many queries and MapReduce tasks are running on HBase, which compromises HBase performance and even causes service rejection. You can configure parameters to limit the maximum number of sessions that can be established between the client and the HBase server to achieve HBase overload protection.
Improved Disaster Recovery¶
The disaster recovery (DR) capabilities between the active and standby clusters can enhance HA of the HBase data. The active cluster provides data services and the standby cluster backs up data. If the active cluster is faulty, the standby cluster takes over data services. Compared with the open source replication function, this function is enhanced as follows:
The standby cluster whitelist function is only applicable to pushing data to a specified cluster IP address.
In the open source version, replication is synchronized based on WAL, and data backup is implemented by replaying WAL in the standby cluster. For BulkLoad operations, since no WAL is generated, data will not be replicated to the standby cluster. By recording BulkLoad operations on the WAL and synchronizing them to the standby cluster, the standby cluster can read BulkLoad operation records through WAL and load HFile in the active cluster to the standby cluster to implement data backup.
In the open source version, HBase filters ACLs. Therefore, ACL information will not be synchronized to the standby cluster. By adding a filter (org.apache.hadoop.hbase.replication.SystemTableWALEntryFilterAllowACL), ACL information can be synchronized to the standby cluster. You can configure hbase.replication.filter.sytemWALEntryFilter to enable the filter and implement ACL synchronization.
As for read-only restriction of the standby cluster, only super users within the standby cluster can modify the HBase of the standby cluster. In other words, HBase clients outside the standby cluster can only read the HBase of the standby cluster.
HBase MOB¶
In the actual application scenarios, data in various sizes needs to be stored, for example, image data and documents. Data whose size is smaller than 10 MB can be stored in HBase. HBase can yield the best read-and-write performance for data whose size is smaller than 100 KB. If the size of data stored in HBase is greater than 100 KB or even reaches 10 MB and the same number of data files are inserted, the total data amount is large, causing frequent compaction and split, high CPU consumption, high disk I/O frequency, and low performance.
MOB data (whose size ranges from 100 KB to 10 MB) is stored in a file system (for example, HDFS) in HFile format. The expiredMobFileCleaner and Sweeper tools are used to manage HFiles and save the address and size information about the HFiles to the store of HBase as values. This greatly decreases the compaction and split frequency in HBase and improves performance.
As shown in Figure 3, MOB indicates mobstore stored on HRegion. Mobstore stores keys and values. Wherein, a key is the corresponding key in HBase, and a value is the reference address and data offset stored in the file system. When reading data, mobstore uses its own scanner to read key-value data objects and uses the address and data size information in the value to obtain target data from the file system.
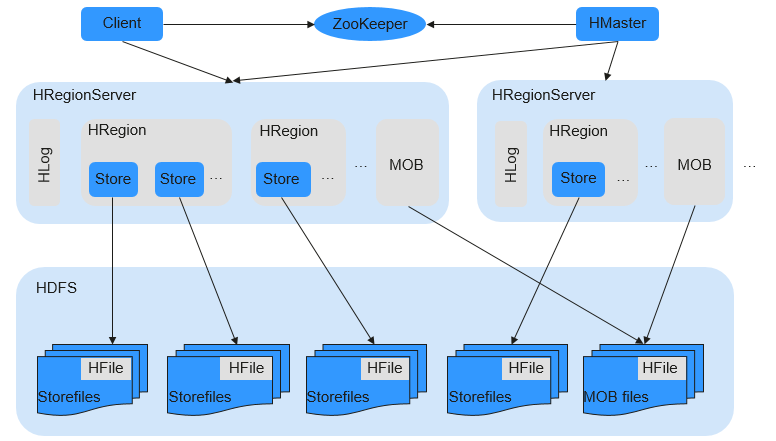
Figure 3 MOB data storage principle¶
HFS¶
HBase FileStream (HFS) is an independent HBase file storage module. It is used in MRS upper-layer applications by encapsulating HBase and HDFS interfaces to provide these upper-layer applications with functions such as file storage, read, and deletion.
In the Hadoop ecosystem, the HDFS and HBase face tough problems in mass file storage in some scenarios:
If a large number of small files are stored in HDFS, the NameNode will be under great pressure.
Some large files cannot be directly stored on HBase due to HBase APIs and internal mechanisms.
HFS is developed for the mixed storage of massive small files and some large files in Hadoop. Simply speaking, massive small files (smaller than 10 MB) and some large files (greater than 10 MB) need to be stored in HBase tables.
For such a scenario, HFS provides unified operation APIs similar to HBase function APIs.
Multiple RegionServers Deployed on the Same Server¶
Multiple RegionServers can be deployed on one node to improve HBase resource utilization.
If only one RegionServer is deployed, resource utilization is low due to the following reasons:
A RegionServer supports a limited number of regions, and therefore memory and CPU resources cannot be fully used.
A single RegionServer supports a maximum of 20 TB data, of which two copies require 40 TB, and three copies require 60 TB. In this case, 96 TB capacity cannot be used up.
Poor write performance: One RegionServer is deployed on a physical server, and only one HLog exists. Only three disks can be written at the same time.
The HBase resource utilization can be improved when multiple RegionServers are deployed on the same server.
A physical server can be configured with a maximum of five RegionServers. The number of RegionServers deployed on each physical server can be configured as required.
Resources such as memory, disks, and CPUs can be fully used.
A physical server supports a maximum of five HLogs and allows data to be written to 15 disks at the same time, significantly improving write performance.
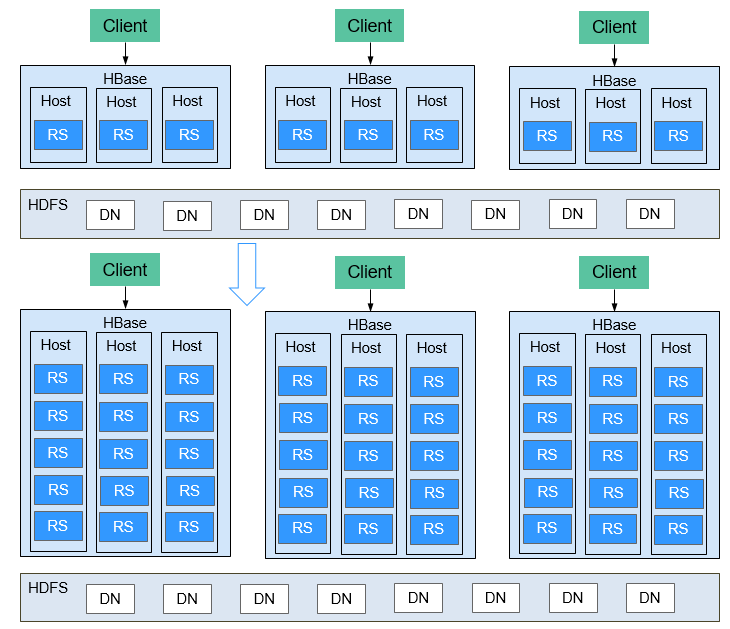
Figure 4 Improved HBase resource utilization¶
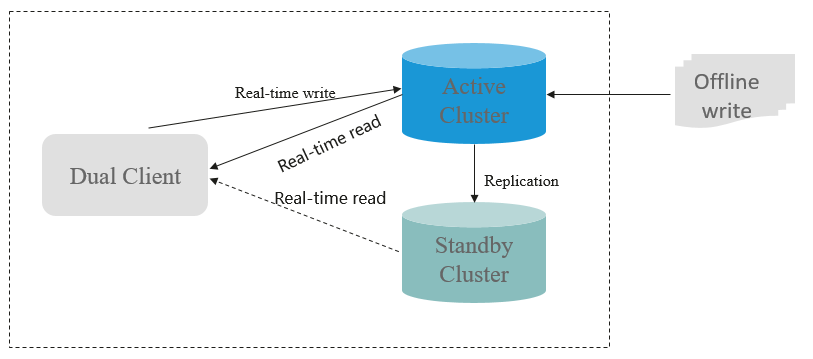
HBase Dual-Read¶
In the HBase storage scenario, it is difficult to ensure 99.9% query stability due to GC, network jitter, and bad sectors of disks. The HBase dual-read feature is added to meet the requirements of low glitches during large-data-volume random read.
The HBase dual-read feature is based on the DR capability of the active and standby clusters. The probability that the two clusters generate glitches at the same time is far less than that of one cluster. The dual-cluster concurrent access mode is used to ensure query stability. When a user initiates a query request, the HBase service of the two clusters is queried at the same time. If the active cluster does not return any result after a period of time (the maximum tolerable glitch time), the data of the cluster with the fastest response can be used. The following figure shows the working principle.