Basic Principles¶
Introduction to Doris¶
Doris is a high-performance, real-time analytical database based on MPP architecture, known for its extreme speed and ease of use. It can return query results of mass data in sub-seconds and can support high-concurrency point queries and high-throughput complex analysis. All this makes Apache Doris an ideal tool for report analysis, ad-hoc query, unified data warehouse, and data lake query acceleration. On Doris, users can build various applications, such as user behavior analysis, AB test platform, log retrieval analysis, user portrait analysis, and order analysis. For more information, see Apache Doris.
Doris Architecture¶
The following figure shows the overall architecture of Doris. The frontend (FE) and backend (BE) nodes can be expanded horizontally and infinitely.
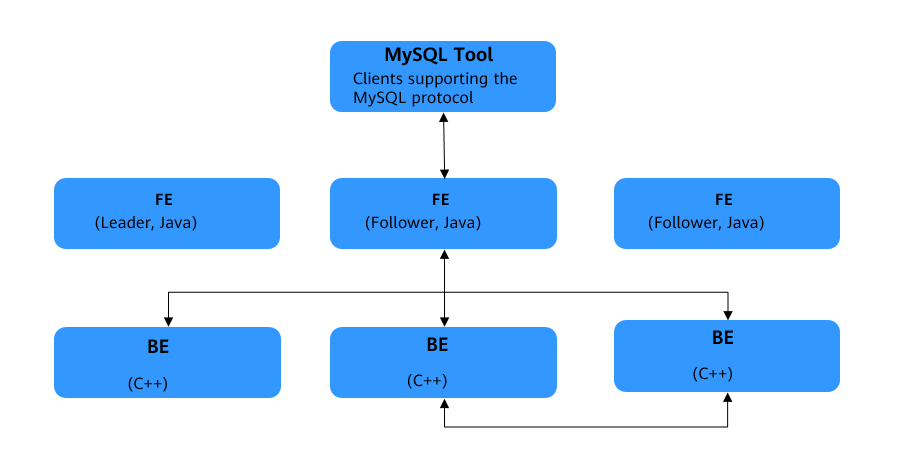
Figure 1 Doris architecture¶
Parameter | Description |
|---|---|
MySQL Tools | Doris is fully compatible with MySQL syntax and can be accessed by various client tools. It also supports standard SQL statements and can seamlessly connect to BI tools. |
FE | Frontend nodes process user access requests, plan query parsing, and manage metadata and nodes. |
BE | Backend nodes store data, execute query plans, and balance load among copies. |
Leader | Leader is a role elected from Follower nodes. |
Follower | Follower nodes receive metadata logs, which must be written successfully in most nodes. |
Doris uses the MPP model for inter-node and intra-node parallel execution, making it suitable for distributed joins of large tables.
It also supports vectorized query execution engines, adaptive query execution (AQE) technology, optimization strategies that combine CBO and RBO, and hot data cache queries.
Basic Concepts¶
In Doris, data is logically described in the form of tables.
Rows and Columns
A table consists of rows and columns.
Row: a row of user data.
Column: different fields in a row of data.
Columns can be classified into two types: keys and values. From the service perspective, Key and Value correspond to dimension columns and metric columns, respectively. In the aggregation model, rows with the same Key column are aggregated into one row. How Value columns are aggregated is specified by a user when the table is created.
Tablets and Partitions
In the Doris storage engine, user data is horizontally divided into several tablets (also called data buckets). Each tablet contains several rows of data. The data between the individual tablets does not intersect and is physically stored independently.
Multiple tablet logically belong to different partitions. A tablet belongs to only one partition, but a partition can contain multiple tablets. Since the tablets are physically stored independently, the partitions can be seen as physically independent, too. Tablet is the smallest physical storage unit for data operations such as movement and replication.
Multiple partitions form a table. A partition can be regarded as the smallest logical unit for management. Data can be imported or deleted only for one partition.
Data Models
Doris data models are classified into three types: Aggregate, Unique, and Duplicate.
Aggregate Model
When data is imported, rows with the same Key column are aggregated, and the Value columns are aggregated based on the AggregationType configured by users. AggregationType has the following modes:
SUM: Sum up the values in multiple rows.
REPLACE: Replace the previous value with the newly imported value.
MAX: Keep the maximum value.
MIN: Keep the minimum value.
Unique Model
In some multi-dimensional analysis scenarios, users are highly concerned about how to create uniqueness constraints for the Primary Key. The Unique model is introduced to solve this problem.
Merge on Read
The merge on read implementation in the Unique model is equivalent to Replace implementation in the Aggregate model. The internal implementation and data storage method are the same.
Merge on Write
The Merge on Write implementation of the Unique model is completely different from that of the Aggregate model. It can deliver better performance (almost like that of the Duplicate model) in aggregation queries with primary key limitations. This implementation is particularly suitable for aggregation queries and those using indexes to filter out large scale data.
In a Unique table where Merge on Write is enabled, overwritten and updated data is marked and deleted during data import, and new data is written to a new file. During a query, all data marked for deletion is filtered out at the file level, and the read data is the latest data. This eliminates the data aggregation process in Merge on Read and supports pushdown of multiple predicates in many cases. Performance can be greatly improved in many scenarios, especially in the case of aggregation queries.
Duplicate Model
In some multi-dimensional analysis scenarios, primary keys and data aggregation are not required. Duplicate models can be introduced to meet such requirements.
Different from the Aggregate and Unique models, the Duplicate model stores the data as they are and executes no aggregation. Even if there are two identical rows of data, they will both be retained. The DUPLICATE KEY in the CREATE TABLE statement is only used to specify based on which columns the data are sorted.
Data Model Selection
The data model is established when the table is created and cannot be modified. Therefore, it is important to select a proper data model.
The Aggregate model aggregates data in advance, greatly reducing data scanning and calculation workload. Therefore, it is suitable for reporting query business, which has fixed schema. However, this model is not user-friendly for count(*) queries. Since the aggregation method on the Value column is fixed, semantic correctness should be considered in other types of aggregation queries.
The Unique model ensures that the primary key is unique when it is required. However, pre-aggregation such as Rollup cannot be used in this case.
The Unique model supports only the update of an entire row. If you need to update both the unique primary key constraint and some columns (for example, importing multiple source tables to one Doris table), you can use the Aggregate model and set the aggregation type of non-primary key columns to REPLACE_IF_NOT_NULL.
Duplicate is suitable for ad-hoc queries in any dimension. Although pre-aggregation cannot be used, Duplicate is not restricted by the aggregation model and can make full use of the advantages of the column-store model, that is, only related columns are read, and not all key columns need to be read.