Streamlining Shuffle¶
Scenario¶
During the shuffle procedure of MapReduce, the Map task writes intermediate data into disks, and the Reduce task copies and adds the data to the reduce function. Hadoop provides lots of parameters for the optimization.
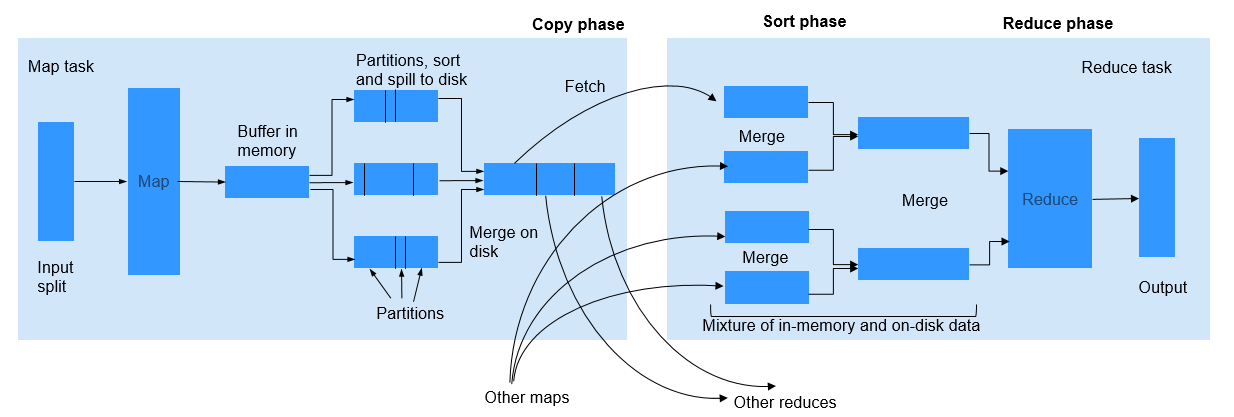
Figure 1 Shuffle process¶
Procedure¶
Improving Performance in Map Phase
Determine the memory used by Map.
To determine whether Map has sufficient memory, check the number of GCs and the ratio of the GC time over the total task time in counters of completed jobs. Normally, the GC time cannot exceed 10% of the task time (that is, GC time elapsed (ms)/CPU time spent (ms) < 10%).
You can improve Map performance by adjusting the following parameters.
Parameter portal:
On the All Configurations page of the Yarn service, enter a parameter name in the search box. For details, see Modifying Cluster Service Configuration Parameters.
Table 1 Parameter description¶ Parameter
Description
Default Value
mapreduce.map.memory.mb
Memory restriction of a Map task.
4096
mapreduce.map.java.opts
JVM parameter of the Map subtask. If this parameter is set, it will replace the mapred.child.java.opts parameter. If -Xmx is not set, the value of Xmx is calculated based on mapreduce.map.memory.mb and mapreduce.job.heap.memory-mb.ratio.
For versions earlier than MRS 3.x: -Xmx2048M -Djava.net.preferIPv4Stack=true
For MRS cluster 3.x and later versions:
Clusters with Kerberos authentication enabled: -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv6Addresses=false -Djava.security.krb5.conf=${BIGDATA_HOME}/common/runtime/krb5.conf -Dbeetle.application.home.path=${BIGDATA_HOME}/common/runtime/security/config
Clusters with Kerberos authentication disabled: -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv6Addresses=false -Dbeetle.application.home.path=${BIGDATA_HOME}/common/runtime/security/config
It is recommended that the -Xmx in mapreduce.map.java.opts is 0.8 times the value of mapreduce.map.memory.mb.
Using Combiner
Combiner is an optional procedure in the Map phase, in which the intermediate results with the same key value are combined. Generally, set the reduce class to combiner. Combiner helps reduce the intermediate result output of Map, thereby consuming less network bandwidth during the shuffle process. You can use the following API to set a combiner class for a specific job.
Table 2 Combiner API¶ Class
API
Description
org.apache.hadoop.mapreduce.Job
public void setCombinerClass(Class<? extends Reducer> cls)
API used to set a combiner class for a specific job.
Improving Performance in Copy Phase
Compress data.
Compress the intermediate output of Map. Data compression reduces the data to be transferred over the network. However, data compression and decompression consume more CPU. Determine whether to compress the intermediate results of Map based on site requirements. If a task is bandwidth-intensive, data compression improves processing performance. As for the bulkload optimization, compression of the intermediate output improves the performance by 60%.
To improve copy performance, set mapreduce.map.output.compress to true and mapreduce.map.output.compress.codec to org.apache.hadoop.io.compress.SnappyCodec.
Improving Performance in Merge Phase
To improve merge performance, configure the following parameters to reduce the number of times that Reduce writes data to disks.
Parameter portal:
On the All Configurations page of the Yarn service, enter a parameter name in the search box. For details, see Modifying Cluster Service Configuration Parameters.
Table 3 Parameter description¶ Parameter
Description
Default Value
mapreduce.reduce.merge.inmem.threshold
Threshold of the number of files for the in-memory merge process. When the accumulated number of files reaches the threshold, the process of in-memory merge and spilling to disks is initiated. If the value is less than or equal to 0, the threshold does not take effect and the merge is triggered only based on the RAMFS memory usage.
1000
mapreduce.reduce.shuffle.merge.percent
Usage threshold for initiating in-memory merge, indicating the percentage of memory allocated to the Map outputs (defined by mapreduce.reduce.shuffle.input.buffer.percent).
0.66
mapreduce.reduce.shuffle.input.buffer.percent
Percentage of memory to be allocated from the maximum heap size to storing Map outputs during the Shuffle.
0.70
mapreduce.reduce.input.buffer.percent
Percentage of memory (relative to the maximum heap size) to retain Map outputs during the Reduce. When the Shuffle is completed, all remaining Map outputs in memory must use less than this threshold before the Reduce begins.
0.0