ClickHouse Table Engine Overview¶
Background¶
Table engines play a key role in ClickHouse to determine:
Where to write and read data
Supported query modes
Whether concurrent data access is supported
Whether indexes can be used
Whether multi-thread requests can be executed
Parameters used for data replication
This section describes MergeTree and Distributed engines, which are the most important and frequently used ClickHouse table engines.
MergeTree Family¶
Engines of the MergeTree family are the most universal and functional table engines for high-load tasks. They have the following key features:
Data is stored by partition and block based on partitioning keys.
Data index is sorted based on primary keys and the ORDER BY sorting keys.
Data replication is supported by table engines prefixed with Replicated.
Data sampling is supported.
When data is written, a table with this type of engine divides data into different folders based on the partitioning key. Each column of data in the folder is an independent file. A file that records serialized index sorting is created. This structure reduces the volume of data to be retrieved during data reading, greatly improving query efficiency.
MergeTree
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2 ) ENGINE = MergeTree() ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...] [SETTINGS name=value, ...]
Example:
CREATE TABLE default.test ( name1 DateTime, name2 String, name3 String, name4 String, name5 Date, ... ) ENGINE = MergeTree() PARTITION BY toYYYYMM(name5) ORDER BY (name1, name2) SETTINGS index_granularity = 8192
Parameters in the example are described as follows:
ENGINE = MergeTree(): specifies the MergeTree engine.
PARTITION BY toYYYYMM(name4): specifies the partition. The sample data is partitioned by month, and a folder is created for each month.
ORDER BY: specifies the sorting field. A multi-field index can be sorted. If the first field is the same, the second field is used for sorting, and so on.
index_granularity = 8192: specifies the index granularity. One index value is recorded for every 8,192 data records.
If the data to be queried exists in a partition or sorting field, the data query time can be greatly reduced.
ReplacingMergeTree
Different from MergeTree, ReplacingMergeTree deletes duplicate entries with the same sorting key. ReplacingMergeTree is suitable for clearing duplicate data to save space, but it does not guarantee the absence of duplicate data. Generally, it is not recommended.
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = ReplacingMergeTree([ver]) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
SummingMergeTree
When merging data parts in SummingMergeTree tables, ClickHouse merges all rows with the same primary key into one row that contains summed values for the columns with the numeric data type. If the primary key is composed in a way that a single key value corresponds to large number of rows, storage volume can be significantly reduced and the data query speed can be accelerated.
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = SummingMergeTree([columns]) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
Example:
Create a SummingMergeTree table named testTable.
CREATE TABLE testTable ( id UInt32, value UInt32 ) ENGINE = SummingMergeTree() ORDER BY id
Insert data into the table.
INSERT INTO testTable Values(5,9),(5,3),(4,6),(1,2),(2,5),(1,4),(3,8); INSERT INTO testTable Values(88,5),(5,5),(3,7),(3,5),(1,6),(2,6),(4,7),(4,6),(43,5),(5,9),(3,6);
Query all data in unmerged parts.
SELECT * FROM testTable ┌─id─┬─value─┐ │ 1 │ 6 │ │ 2 │ 5 │ │ 3 │ 8 │ │ 4 │ 6 │ │ 5 │ 12 │ └───┴──── ┘ ┌─id─┬─value─┐ │ 1 │ 6 │ │ 2 │ 6 │ │ 3 │ 18 │ │ 4 │ 13 │ │ 5 │ 14 │ │ 43 │ 5 │ │ 88 │ 5 │ └───┴──── ┘
If ClickHouse has not summed up all rows and you need to aggregate data by ID, use the sum function and GROUP BY statement.
SELECT id, sum(value) FROM testTable GROUP BY id ┌─id─┬─sum(value)─┐ │ 4 │ 19 │ │ 3 │ 26 │ │ 88 │ 5 │ │ 2 │ 11 │ │ 5 │ 26 │ │ 1 │ 12 │ │ 43 │ 5 │ └───┴───────┘
Merge rows manually.
OPTIMIZE TABLE testTable
Query data in the testTable table again.
SELECT * FROM testTable ┌─id─┬─value─┐ │ 1 │ 12 │ │ 2 │ 11 │ │ 3 │ 26 │ │ 4 │ 19 │ │ 5 │ 26 │ │ 43 │ 5 │ │ 88 │ 5 │ └───┴──── ┘
SummingMergeTree uses the ORDER BY sorting keys as the condition keys to aggregate data. That is, if sorting keys are the same, data records are merged into one and the specified merged fields are aggregated.
Data is pre-aggregated only when merging is executed in the background, and the merging execution time cannot be predicted. Therefore, it is possible that some data has been pre-aggregated and some data has not been aggregated. Therefore, the GROUP BY statement must be used during aggregation.
AggregatingMergeTree
AggregatingMergeTree is a pre-aggregation engine used to improve aggregation performance. When merging partitions, the AggregatingMergeTree engine aggregates data based on predefined conditions, calculates data based on predefined aggregate functions, and saves the data in binary format to tables.
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = AggregatingMergeTree() [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [TTL expr] [SETTINGS name=value, ...]
Example:
You do not need to set the AggregatingMergeTree parameter separately. When partitions are merged, data in each partition is aggregated based on the ORDER BY sorting key. You can set the aggregate functions to be used and column fields to be calculated by defining the AggregateFunction type, as shown in the following example:
create table test_table ( name1 String, name2 String, name3 AggregateFunction(uniq,String), name4 AggregateFunction(sum,Int), name5 DateTime ) ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(name5) ORDER BY (name1,name2) PRIMARY KEY name1;
When data of the AggregateFunction type is written or queried, the *state and *merge functions need to be called. The asterisk (
*) indicates the aggregate functions used for defining the field type. For example, the uniq and sum functions are specified for the name3 and name4 fields defined in the test_table, respectively. Therefore, you need to call the uniqState and sumState functions and run the INSERT and SELECT statements when writing data into the table.insert into test_table select '8','test1',uniqState('name1'),sumState(toInt32(100)),'2021-04-30 17:18:00'; insert into test_table select '8','test1',uniqState('name1'),sumState(toInt32(200)),'2021-04-30 17:18:00';
When querying data, you need to call the corresponding functions uniqMerge and sumMerge.
select name1,name2,uniqMerge(name3),sumMerge(name4) from test_table group by name1,name2; ┌─name1─┬─name2─┬─uniqMerge(name3)─┬─sumMerge(name4)─┐ │ 8 │ test1 │ 1 │ 300 │ └──── ┴──── ┴──────────┴───────── ┘
AggregatingMergeTree is more commonly used with materialized views, which are query views of other data tables at the upper layer.
CollapsingMergeTree
CollapsingMergeTree defines a Sign field to record status of data rows. If Sign is 1, the data in this row is valid. If Sign is -1, the data in this row needs to be deleted.
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = CollapsingMergeTree(sign) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
VersionedCollapsingMergeTree
The VersionedCollapsingMergeTree engine adds Version to the table creation statement to record the mapping between a state row and a cancel row in case that rows are out of order. The rows with the same primary key, same Version, and opposite Sign will be deleted during compaction.
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = VersionedCollapsingMergeTree(sign, version) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
GraphiteMergeTree
The GraphiteMergeTree engine is used to store data in the time series database Graphite.
Syntax for creating a table:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( Path String, Time DateTime, Value <Numeric_type>, Version <Numeric_type> ... ) ENGINE = GraphiteMergeTree(config_section) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
Replicated*MergeTree Engines¶
All engines of the MergeTree family in ClickHouse prefixed with Replicated become MergeTree engines that support replicas.
Replicated series engines use ZooKeeper to synchronize data. When a replicated table is created, all replicas of the same shard are synchronized based on the information registered with ZooKeeper.
Template for creating a Replicated engine:
ENGINE = Replicated*MergeTree('Storage path in ZooKeeper','Replica name', ...)
Two parameters need to be specified for a Replicated engine:
Storage path in ZooKeeper: specifies the path for storing table data in ZooKeeper. The path format is /clickhouse/tables/{shard}/Database name/Table name.
Replica name: Generally, {replica} is used.
For details about the example, see Creating a ClickHouse Table.
Distributed Engine¶
The Distributed engine does not store any data. It serves as a transparent proxy for data shards and can automatically transmit data to each node in the cluster. Distributed tables need to work with other local data tables. Distributed tables distribute received read and write tasks to each local table where data is stored.
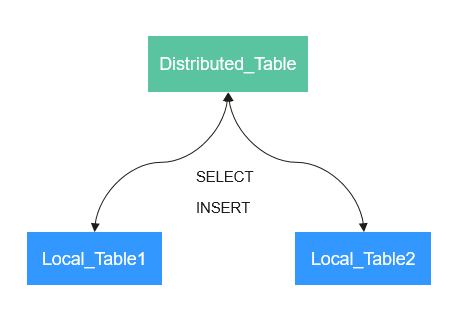
Figure 1 Working principle of the Distributed engine¶
Template for creating a Distributed engine:
ENGINE = Distributed(cluster_name, database_name, table_name, [sharding_key])
Parameters of a distributed table are described as follows:
cluster_name: specifies the cluster name. When a distributed table is read or written, the cluster configuration information is used to search for the corresponding ClickHouse instance node.
database_name: specifies the database name.
table_name: specifies the name of a local table in the database. It is used to map a distributed table to a local table.
sharding_key (optional): specifies the sharding key, based on which a distributed table distributes data to each local table.
Example:
-- Create a ReplicatedMergeTree local table named test.
CREATE TABLE default.test ON CLUSTER default_cluster_1
(
`EventDate` DateTime,
`id` UInt64
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/default/test', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY id
-- Create a distributed table named test_all based on the local table test.
CREATE TABLE default.test_all ON CLUSTER default_cluster_1
(
`EventDate` DateTime,
`id` UInt64
)
ENGINE = Distributed(default_cluster_1, default, test, rand())
Rules for creating a distributed table:
When creating a distributed table, add ON CLUSTER cluster_name to the table creation statement so that the statement can be executed once on a ClickHouse instance and then distributed to all instances in the cluster for execution.
Generally, a distributed table is named in the following format: Local table name_all. It forms a one-to-many mapping with local tables. Then, multiple local tables can be operated using the distributed table proxy.
Ensure that the structure of a distributed table is the same as that of local tables. If they are inconsistent, no error is reported during table creation, but an exception may be reported during data query or insertion.