Configuring ApplicationMaster Work Preserving¶
Scenario¶
In YARN, ApplicationMasters run on NodeManagers just like every other container (ignoring unmanaged ApplicationMasters in this context). ApplicationMasters may break down, exit, or shut down. If an ApplicationMaster node goes down, ResourceManager kills all the containers of ApplicationAttempt, including containers running on NodeManager. ResourceManager starts a new ApplicationAttempt node on another compute node.
For different types of applications, we want to handle ApplicationMaster restart events in different ways. MapReduce applications aim to prevent task loss but allow the loss of the currently running container. However, for the long-period YARN service, users may not want the service to stop due to the ApplicationMaster fault.
YARN can retain the status of the container when a new ApplicationAttempt is started. Therefore, running jobs can continue to operate without faults.
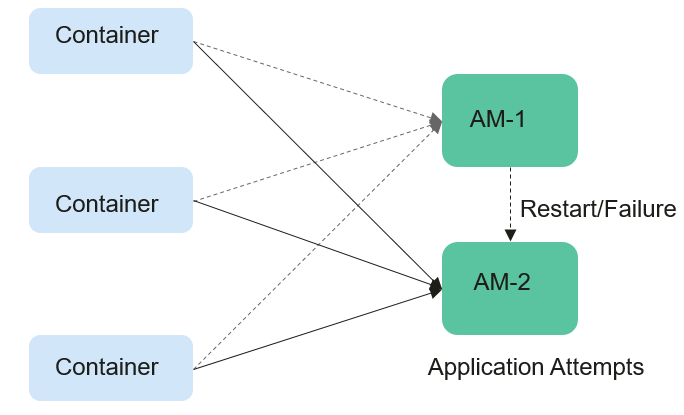
Figure 1 ApplicationMaster job preserving¶
Configuration Description¶
Go to the All Configurations page of Yarn and enter a parameter name in the search box by referring to Modifying Cluster Service Configuration Parameters.
Set the following parameters based on Table 1.
Parameter | Description | Default Value |
|---|---|---|
yarn.app.mapreduce.am.work-preserve | Whether to enable the ApplicationMaster job retention feature. | false |
yarn.app.mapreduce.am.umbilical.max.retries | Maximum number of attempts to restore a running container in the ApplicationMaster job retention feature. | 5 |
yarn.app.mapreduce.am.umbilical.retry.interval | Specifies the interval at which a running container attempts to recover in the ApplicationMaster job retention feature. Unit: millisecond | 10000 |
yarn.resourcemanager.am.max-attempts | The number of retries of ApplicationMaster. Increasing the number of retries prevents ApplicationMaster startup failures caused by insufficient resources. This applies to global settings of all ApplicationMasters. Each ApplicationMaster can use an API to set an independent maximum number of retries. However, the number of retries cannot be greater than the global maximum number of retries. If the value is greater than the global maximum number of retries, the ResourceManager overwrites the value The value must be greater than or equal to 1. | 2 |