Configuring LIFO for Kafka¶
Scenario¶
If the Spark Streaming application is connected to Kafka, after the Spark Streaming application is terminated abnormally and restarted from the checkpoint, the system preferentially processes the tasks that are not completed before the application is terminated (Period A) and the tasks generated based on data that enters Kafka during the period (Period B) from the application termination to the restart. Then the application processes the tasks generated based on data that enters Kafka after the application is restarted (Period C). For data that enters Kafka in period B, Spark generates a corresponding number of tasks based on the end time (batch time). The first task reads all data, but other tasks may not read data. As a result, the task processing pressure is uneven.
If the tasks in Period A and Period B are processed slowly, the processing of tasks in period C is affected. To cope with the preceding scenario, Spark provides the last-in first-out (LIFO) function for Kafka.
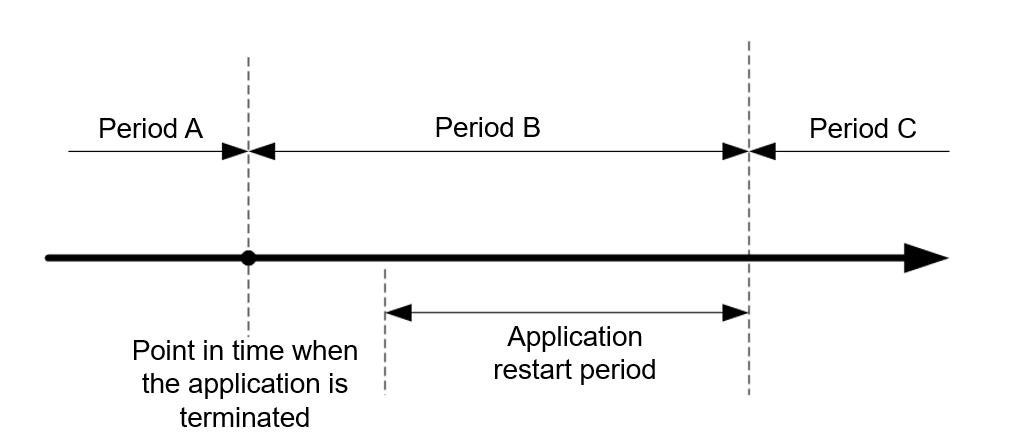
Figure 1 Time axis for restarting the Spark Streaming application¶
After this function is enabled, Spark preferentially schedules tasks in Period C. If there are multiple tasks in Period C, Spark schedules and executes the tasks in the sequence of task generation. Then Spark executes the tasks in Periods A and B. For data that enters Kafka in Period B, Spark generates tasks based on the end time and evenly distributes all data that enters Kafka in this period to each task to avoid uneven task processing pressure.
Constraints:
This function applies only to the direct mode of Spark Streaming, and the execution result does not depend on the processing result of the previous batch (that is, stateless operation, for example, updatestatebykey). Multiple data input streams must be comparatively independent from each other. Otherwise, the result may change after the data is divided.
The Kafka LIFO function can be enabled only when the application is connected to the Kafka input source.
If both Kafka LIFO and flow control functions are enabled when the application is submitted, the flow control function is not enabled for the data that enters Kafka in Period B to ensure that the task scheduling priority for reading the data is the lowest. Flow control is enabled for the tasks in Period C after the application is restarted.
Configuration¶
Configure the following parameters in the spark-defaults.conf file on the Spark driver.
Parameter | Description | Default Value |
|---|---|---|
spark.streaming.kafka.direct.lifo | Specifies whether to enable the LIFO function of Kafka. | false |
spark.streaming.kafka010.inputstream.class | Obtains the decoupled class on FusionInsight. | org.apache.spark.streaming.kafka010.HWDirectKafkaInputDStream |