Configuring the Distributed Cache¶
Scenarios¶
Distributed caching is useful in the following scenarios:
Rolling Upgrade
During the upgrade, applications must keep the text content (JAR file or configuration file) unchanged. The content is not based on Yarn of the current version, but on the version when it is submitted. This is a challenging issue. Generally, applications (such as MapReduce, Hive, and Tez) need to be installed locally. Libraries need to be installed on all cluster servers (clients and servers). When a rolling upgrade or downgrade starts in the cluster, the version of the locally installed library changes during application running. During the rolling upgrade, only a few NodeManagers are upgraded first. These NodeManagers obtain the software of the latest version. This leads to inconsistent behavior and can result in run-time errors.
Co-existence of Multiple Yarn Versions
Cluster administrators may run tasks that use multiple versions of Yarn and Hadoop JARs in a cluster. However, this task is difficult to be implemented because the JARs have been localized and have only one version.
The MapReduce application framework can be deployed through the distributed cache and does not depend on the static version copied during installation. Therefore, you can store multiple versions of Hadoop in HDFS and configure the mapred-site.xml file to specify the default version used by the task. You can run different versions of MapReduce by setting proper configuration attributes without using the versions deployed in the cluster.
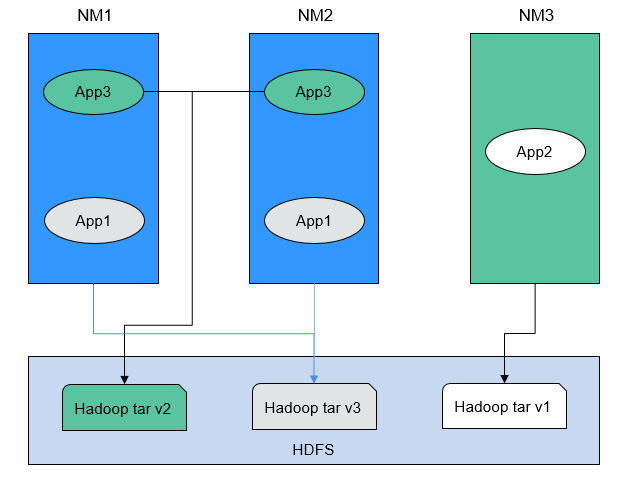
Figure 1 Clusters with NodeManagers and Applications of multiple versions¶
As shown in Figure 1, the application can use Hadoop JARs in HDFS instead of the local version. Therefore, during the rolling upgrade, even if NodeManager has been upgraded, the application can still run Hadoop of the earlier version.
Configuration Description¶
Save the MapReduce .tar package of the specified version to a directory that can be accessed by applications in HDFS, as shown in the following command.
$HADOOP_HOME/bin/hdfs dfs -put hadoop-x.tar.gz /mapred/framework/
Set parameters in the mapred-site.xml file based on Table 1.
Table 1 Distributed cache parameters¶ Parameter
Description
Default Value
mapreduce.application.framework.path
Indicates the URL directing to the archive location.
Note
This property can also create an alias for the archive if the URL fragment identity name is specified as follows. In this example, the alias is set to mr-framework.
<property> <name>mapreduce.application.framework.path</name> <value>hdfs:/mapred/framework/hadoop-x.tar.gz#mr-framework</value> </property>
NA
mapreduce.application.classpath
Indicates the parameter property, which contains the MapReduce JARs in the class directory.
Note
For example, the alias mr-framework used in the framework path is used to match the directory.
<property> <name>mapreduce.application.classpath</name> <value>$PWD/mr-framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-framework/hadoop/share/hadoop/common/*:$PWD/mr-framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/lib/*:/etc/hadoop/conf/secure</value></property>
N/A
You can upload MapReduce tarballs of multiple versions to HDFS. Different mapred-site.xml files indicate different locations. After that, you can run tasks for a specific mapred-site.xml file. The following is an example of running an MapReduce task for the MapReduce tarball of the x version:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-.jar* pi -conf etc/hadoop-x/mapred-site.xml 10 10