Hive output¶
Overview¶
The Hive Output operator exports existing fields to specified columns of a Hive table.
Input and Output¶
Input: fields to be exported
Output: Hive table
Parameters¶
Parameter | Description | Node Type | Mandatory | Default Value |
|---|---|---|---|---|
Hive file storage format | Hive configuration file storage format. CSV, ORC, and RC are supported at present. Note
| enum | Yes | CSV |
Hive file compression format | Hive table file compression format. Select a format from the drop-down list. If you select NONE or do not set this parameter, data is not compressed. | enum | Yes | NONE |
Hive ORC file version | Version of the ORC file (when the storage format of the Hive table file is ORC). | enum | Yes | 0.12 |
Output delimiter | Delimiter. | string | Yes | None. |
Output fields | Information about output fields:
| map | Yes | None |
Data Processing Rule¶
The field values are exported to the Hive table.
If one or more columns are specified as partition columns, the Partition Handlers feature is displayed on the To page in Step 4 of the job configuration. Partition Handlers specifies the number of handlers for processing data partitioning.
If no column is designated as partition columns, input data does not need to be partitioned, and Partition Handlers is hidden by default.
Example¶
Use the CSV File Input operator to generate two fields A and B.
The following figure shows the source file.
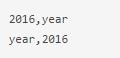
Configure the Hive Output operator to export a_str and b_str to the Hive table.
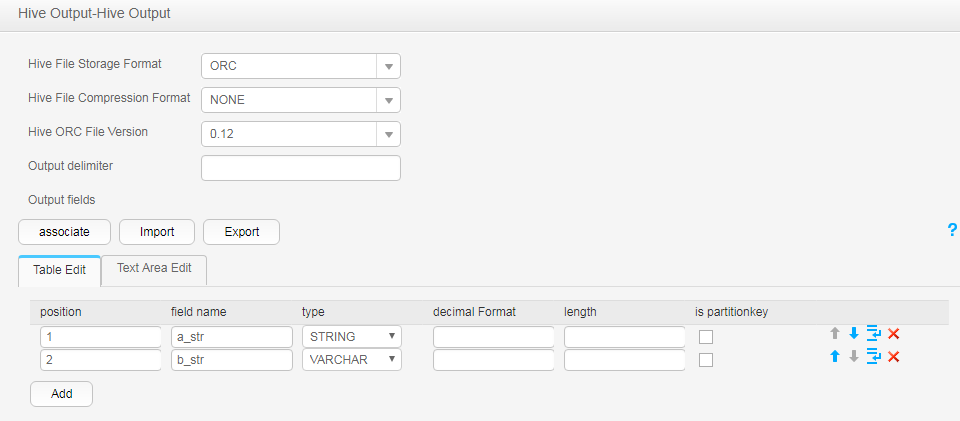
After the execution is complete, view the table data.