UDF Overview¶
IoTDB provides multiple built-in functions and user-defined functions (UDFs) to meet users' computing requirements.
UDF Types¶
Table 1 lists the UDF types supported by IoTDB.
Type | Description |
|---|---|
User-defined timeseries generating function (UDTF) | This type of function can take multiple time series as input and generate one time series, which can contain any number of data points. |
UDTF¶
To write a UDTF, you need to inherit the org.apache.iotdb.db.query.udf.api.UDTF class and implement at least the beforeStart method and one transform method.
Table 2 describes all interfaces that can be implemented by users.
Interface Definition | Description | Mandatory |
|---|---|---|
void validate(UDFParameterValidator validator) throws Exception | This method is used to validate UDFParameters and is executed before beforeStart is called. | No |
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception | This is an initialization method used to call the user-defined initialization behavior before the UDTF processes the input data. Each time a user executes a UDTF query, the framework constructs a new UDF instance, and this method is called. It is called only once in the lifecycle of each UDF instance. | Yes |
void transform(Row row, PointCollector collector) throws Exception | This method is called by the framework. When you choose to use the RowByRowAccessStrategy strategy in beforeStart to consume raw data, this data processing method is called. The input data is passed in by Row, and the result is output by PointCollector. You need to call the data collection method provided by collector in this method to determine the output data. | Use either this method or transform(RowWindow rowWindow, PointCollector collector). |
void transform(RowWindow rowWindow, PointCollector collector) throws Exception | This method is called by the framework. When you choose to use the SlidingSizeWindowAccessStrategy or SlidingTimeWindowAccessStrategy strategy in beforeStart to consume raw data, this data processing method will be called. The input data is passed in by RowWindow, and the result is output by PointCollector. You need to call the data collection method provided by collector in this method to determine the output data. | Use either this method or transform(Row row, PointCollector collector). |
void terminate(PointCollector collector) throws Exception | This method is called by the framework. This method is called after all transform calls have been executed and before beforeDestory is called. In a single UDF query, this method will be called only once. You need to call the data collection method provided by collector in this method to determine the output data. | No |
void beforeDestroy() | This method is called by the framework after the last input data is processed, and will be called only once in the lifecycle of each UDF instance. | No |
Calling sequence of each method:
void validate(UDFParameterValidator validator) throws Exception
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception
void transform(Row row, PointCollector collector) throws Exception or void transform(RowWindow rowWindow, PointCollector collector) throws Exception
void terminate(PointCollector collector) throws Exception
void beforeDestroy()
Important
Each time the framework executes a UDTF query, a new UDF instance will be constructed. When the query ends, this UDF instance will be destroyed. Therefore, the internal data of the instances in different UDTF queries (even in the same SQL statement) is isolated. You can maintain some state data in the UDTF without considering the impact of concurrency and other factors.
Interface usage:
void validate(UDFParameterValidator validator) throws Exception
The validate method is used to validate the parameters entered by users.
In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom logic verification.
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception
Using this method, you can do the following things:
Use UDFParameters to get the time series paths and parse the entered key-value pair attributes.
Set information required for running the UDF. That is, set the strategy to access the raw data and set the output data type in UDTFConfigurations.
Create resources, such as creating external connections and opening files.
UDFParameters¶
UDFParameters is used to parse the UDF parameters in SQL statements (the part in the parentheses following the UDF name in the SQL statements). The parameters include two parts. The first part is the path and its data type of the time series to be processed by the UDF. The second part is the key-value pair attributes for customization.
Example:
SELECT UDF(s1, s2, 'key1'='iotdb', 'key2'='123.45') FROM root.sg.d;
Usage:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// parameters
for (PartialPath path : parameters.getPaths()) {
TSDataType dataType = parameters.getDataType(path);
// do something
}
String stringValue = parameters.getString("key1"); // iotdb
Float floatValue = parameters.getFloat("key2"); // 123.45
Double doubleValue = parameters.getDouble("key3"); // null
int intValue = parameters.getIntOrDefault("key4", 678); // 678
// do something
// configurations
// ...
}
UDTFConfigurations¶
You can use UDTFConfigurations to specify the strategy used by the UDF to access raw data and the type of the output time series.
Usage:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
// parameters
// ...
// configurations
configurations
.setAccessStrategy(new RowByRowAccessStrategy())
.setOutputDataType(TSDataType.INT32);
}
The setAccessStrategy method is used to set the strategy used by the UDF to access raw data. The setOutputDataType method is used to set the data type of the output time series.
setAccessStrategy
Note that the raw data access strategy you set here determines which transform method the framework will call. Implement the transform method corresponding to the raw data access strategy. You can also dynamically decide which strategy to set based on the attribute parameters parsed by UDFParameters. Therefore, the two transform methods are also allowed to be implemented in one UDF.
The following are the strategies you can set.
Interface Definition
Description
transform Method to Call
RowByRowAccessStrategy
Processes raw data row by row. The framework calls the transform method once for each row of raw data input. When a UDF has only one input time series, a row of input is a data point in the input time series. When a UDF has multiple input time series, a row of input is a result record of the raw query (aligned by time) on these input time series. (In a row, there may be a column with a value of null, but not all of them are null.)
void transform(Row row, PointCollector collector) throws Exception
SlidingTimeWindowAccessStrategy
Processes a batch of data in a fixed time interval each time. A data batch is called a window. The framework calls the transform method once for each raw data input window. A window may contain multiple rows of data. Each row of data is a result record of the raw query (aligned by time) on these input time series. (In a row, there may be a column with a value of null, but not all of them are null.)
void transform(RowWindow rowWindow, PointCollector collector) throws Exception
SlidingSizeWindowAccessStrategy
Processes raw data batch by batch, and each batch contains a fixed number of raw data rows (except the last batch). A data batch is called a window. The framework calls the transform method once for each raw data input window. A window may contain multiple rows of data. Each row of data is a result record of the raw query (aligned by time) on these input time series. (In a row, there may be a column with a value of null, but not all of them are null.)
void transform(RowWindow rowWindow, PointCollector collector) throws Exception
The construction of RowByRowAccessStrategy does not require any parameters.
SlidingTimeWindowAccessStrategy has multiple constructors, and you can pass the following types of parameters to the constructors:
Start time and end time of the display window on the time axis
Time interval for dividing the time axis (must be positive)
Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
The display window on the time axis is optional. If these parameters are not provided, the start time of the display window will be set to the same as the minimum timestamp of the query result set, and the end time of the display window will be set to the same as the maximum timestamp of the query result set.
The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
The following figure shows the relationship between the three types of parameters.
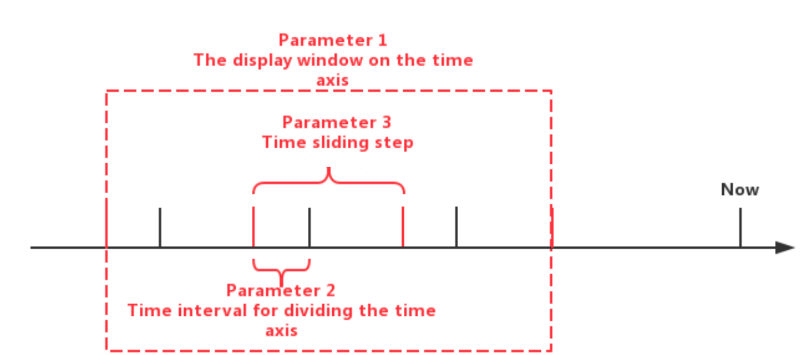
Note that the actual time interval of some of the last time windows may be less than the specified time interval parameter. In addition, the number of data rows in some time windows may be 0. In this case, the framework will also call the transform method for the empty windows.
SlidingSizeWindowAccessStrategy has multiple constructors, and you can pass the following types of parameters to the constructors:
Window size, that is, the number of data rows in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
Sliding step, that is, the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number.)
The sliding step parameter is optional. If this parameter is not provided, the sliding step will be set to the same as the window size.
Note that the type of output time series you set here determines the type of data that PointCollector in the transform method can actually receive. The relationship between the output data type set in setOutputDataType and the actual data output type that PointCollector can receive is as follows.
Output Data Type Set in setOutputDataType
Data Type That PointCollector Can Receive
INT32
int
INT64
long
FLOAT
float
DOUBLE
double
BOOLEAN
boolean
TEXT
java.lang.String and org.apache.iotdb.tsfile.utils.Binary
The type of the output time series of a UDTF is determined at runtime. The UDTF can dynamically determine the type of the output time series according to the type of the input time series.
Example:
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception { // do something // ... configurations .setAccessStrategy(new RowByRowAccessStrategy()) .setOutputDataType(parameters.getDataType(0)); }
void transform(Row row, PointCollector collector) throws Exception
You need to implement this method when you specify the strategy for the UDF to read raw data as RowByRowAccessStrategy in beforeStart.
This method processes one row of raw data at a time. The raw data is input from Row and output by PointCollector. You can choose to output any number of data points in one transform call. Note that the type of the output data points must be the same as you set in the beforeStart method, and the timestamp of the output data points must be strictly monotonically increasing.
The following is a complete UDF example that implements the void transform(Row row, PointCollector collector) throws Exception method. It is an adder that receives two columns of time series as input. When two data points in a row are not null, this UDF will output the algebraic sum of these two data points.
import org.apache.iotdb.db.query.udf.api.UDTF; import org.apache.iotdb.db.query.udf.api.access.Row; import org.apache.iotdb.db.query.udf.api.collector.PointCollector; import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations; import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters; import org.apache.iotdb.db.query.udf.api.customizer.strategy.RowByRowAccessStrategy; import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType; public class Adder implements UDTF { @Override public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) { configurations .setOutputDataType(TSDataType.INT64) .setAccessStrategy(new RowByRowAccessStrategy()); } @Override public void transform(Row row, PointCollector collector) throws Exception { if (row.isNull(0) || row.isNull(1)) { return; } collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1)); } }
void transform(RowWindow rowWindow, PointCollector collector) throws Exception
You need to implement this method when you specify the strategy for the UDF to read raw data as SlidingTimeWindowAccessStrategy or SlidingSizeWindowAccessStrategy.
This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and the container containing this batch of data is called a window. The raw data is input from RowWindow and output by PointCollector. RowWindow can help you access a batch of rows, and it provides a set of interfaces for random access and iterative access to this batch of rows. You can choose to output any number of data points in one transform call. Note that the type of output data points must be the same as you set in the beforeStart method, and the timestamps of output data points must be strictly monotonically increasing.
The following is a complete UDF example that implements the void transform(RowWindow rowWindow, PointCollector collector) throws Exception method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
import java.io.IOException; import org.apache.iotdb.db.query.udf.api.UDTF; import org.apache.iotdb.db.query.udf.api.access.RowWindow; import org.apache.iotdb.db.query.udf.api.collector.PointCollector; import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations; import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters; import org.apache.iotdb.db.query.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy; import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType; public class Counter implements UDTF { @Override public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) { configurations .setOutputDataType(TSDataType.INT32) .setAccessStrategy(new SlidingTimeWindowAccessStrategy( parameters.getLong("time_interval"), parameters.getLong("sliding_step"), parameters.getLong("display_window_begin"), parameters.getLong("display_window_end"))); } @Override public void transform(RowWindow rowWindow, PointCollector collector) throws Exception { if (rowWindow.windowSize() != 0) { collector.putInt(rowWindow.getRow(0).getTime(), rowWindow.windowSize()); } } }
void terminate(PointCollector collector) throws Exception
In some scenarios, a UDF needs to traverse all the raw data to calculate the final output data points. The terminate interface provides support for those scenarios.
This method is called after all transform calls have been executed and before beforeDestory is called. You can implement the transform method to perform pure data processing, and implement the terminate method to output the processing results.
The processing results need to be output by PointCollector. You can choose to output any number of data points in one terminate call. Note that the type of the output data points must be the same as you set in the beforeStart method, and the timestamp of the output data points must be strictly monotonically increasing.
The following is a complete UDF example that implements the void terminate(PointCollector collector) throws Exception method. It takes one time series whose data type is INT32 as input, and outputs the maximum value point of the series.
import java.io.IOException; import org.apache.iotdb.db.query.udf.api.UDTF; import org.apache.iotdb.db.query.udf.api.access.Row; import org.apache.iotdb.db.query.udf.api.collector.PointCollector; import org.apache.iotdb.db.query.udf.api.customizer.config.UDTFConfigurations; import org.apache.iotdb.db.query.udf.api.customizer.parameter.UDFParameters; import org.apache.iotdb.db.query.udf.api.customizer.strategy.RowByRowAccessStrategy; import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType; public class Max implements UDTF { private Long time; private int value; @Override public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) { configurations .setOutputDataType(TSDataType.INT32) .setAccessStrategy(new RowByRowAccessStrategy()); } @Override public void transform(Row row, PointCollector collector) { int candidateValue = row.getInt(0); if (time == null || value < candidateValue) { time = row.getTime(); value = candidateValue; } } @Override public void terminate(PointCollector collector) throws IOException { if (time != null) { collector.putInt(time, value); } } }
void beforeDestroy()
This method is used to terminate a UDF.
This method is called by the framework. For a UDF instance, beforeDestroy will be called after the last record is processed. In the entire lifecycle of the instance, beforeDestroy will be called only once.