Introduction to HetuEngine Cross-Source Function¶
Enterprises usually store massive data, such as from various databases and warehouses, for management and information collection. However, diversified data sources, hybrid dataset structures, and scattered data storage rise the development cost for cross-source query and prolong the cross-source query duration.
HetuEngine provides unified standard SQL statements to implement cross-source collaborative analysis, simplifying cross-source analysis operations.
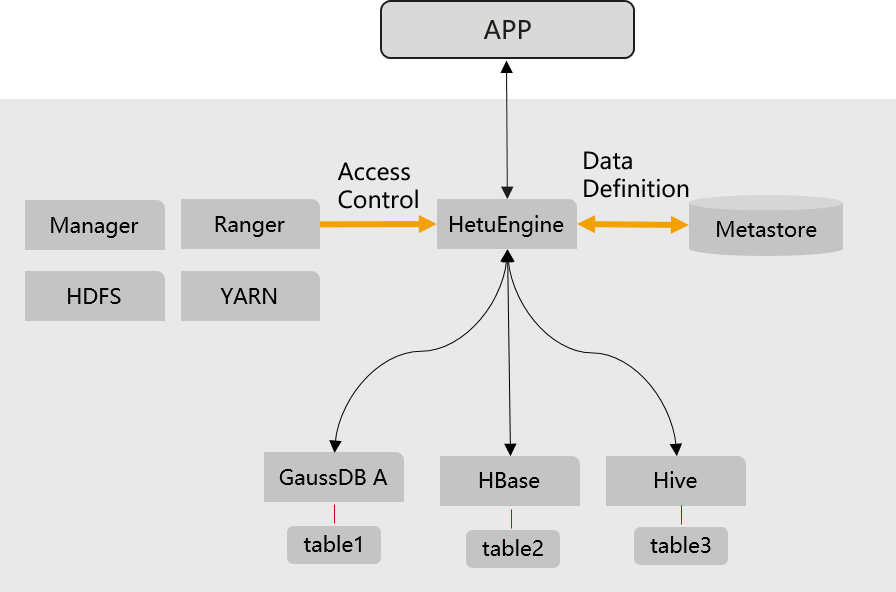
Figure 1 HetuEngine cross-source function¶
Key Technologies and Advantages of the HetuEngine Cross-Source Function¶
Computing pushdown: When HetuEngine is used for cross-source collaborative analysis, HetuEngine enhances the computing pushdown capability from the dimensions listed in the following table to improve access efficiency.
Table 1 Dimensions of HetuEngine computing pushdown¶ Type
Content
Basic Pushed Down
Predicate
Projection
Sub-query
Limit
Aggregation Pushed Down
Group by
Order by
Count
Sum
Min
Max
Operator Pushed Down
<, >
Like
Or
Multi-source heterogeneous data: Collaborative analysis supports both structured data sources such as Hive and GaussDB and unstructured data sources such as HBase and Elasticsearch.
Global metadata: A mapping table is provided to map unstructured schemas to structured schemas, enabling HetuEngine to access HBase using SQL statements. Global management for data source information is provided.
Global permission control: Data source permissions can be opened to Ranger through HetuEngine for centralized management and control.