Configuring Resource Groups¶
Resource Group Introduction¶
The resource group mechanism controls the overall query load of the instance from the perspective of resource allocation and implements queuing policies for queries. Multiple resource groups can be created under a compute instance resource, and each submitted query is assigned to a specific resource group for execution. Before a resource group executes a new query, it checks whether the resource load of the current resource group exceeds the amount of resources allocated to it by the instance. If it is exceeded, new incoming queries are blocked, placed in a queue, or even rejected directly. However, the resource component does not cause the running query to fail.
Application Scenarios of Resource Groups¶
Resource groups are used to manage resources in compute instances. Different resource groups are allocated to different users and queries to isolate resources. This prevents a single user or query from exclusively occupying resources in the compute instance. In addition, the weight and priority of resource components can be configured to ensure that important tasks are executed first. Table 1 describes the typical application scenarios of resource groups.
Typical Scenarios | Solution |
|---|---|
As the number of business teams using the compute instance increases, there is no resource when a team's task becomes more important and does not want to execute a query. | Allocate a specified resource group to each team. Important tasks are assigned to resource groups with more resources. When the sum of the proportions of sub-resource groups is less than or equal to 100%, the resources of a queue cannot be preempted by other resource groups. This is similar to static resource allocation. |
When the instance resource load is high, two users submit a query at the same time. At the beginning, both queries are queuing. When there are idle resources, the query of a specific user can be scheduled to obtain resources first. | Two users are allocated with different resource groups. Important tasks can be allocated to resource groups with higher weights or priorities. The scheduling policy is configured by schedulingPolicy. Different scheduling policies have different resource allocation sequences. |
For ad hoc queries and batch queries, resources can be allocated more properly based on different SQL types. | You can match different resource groups for different query types, such as EXPLAIN, INSERT, SELECT, and DATA_DEFINITION, and allocate different resources to execute the query. |
Enabling a Resource Group¶
When creating a compute instance, add custom configuration parameters to the resource-groups.json file. For details, see 3.e in Creating HetuEngine Compute Instances.
Resource Group Properties¶
For details about how to configure resource group attributes, see Table 2.
Configuration Item | Mandatory | Description |
|---|---|---|
name | Yes | Resource group name |
maxQueued | Yes | Maximum number of queued queries. When this threshold is reached, new queries will be rejected. |
hardConcurrencyLimit | Yes | Maximum number of running queries. |
softMemoryLimit | No | Maximum memory usage of a resource group. When the memory usage reaches this threshold, new tasks are queued. The value can be an absolute value (for example, 10 GB) or a percentage (for example, 10% of the cluster memory). |
softCpuLimit | No | The CPU time that can be used in a period (see the cpuQuotaPeriod parameter in Global Attributes). You must also specify the hardCpuLimit parameter. When the threshold is reached, the CPU resources occupied by the query that occupies the maximum CPU resources in the resource group are reduced. |
hardCpuLimit | No | Maximum CPU time that can be used in a period. |
schedulingPolicy | No | The scheduling policy for a specific query from the queuing state to the running state
When multiple sub-resource groups in a resource group have queuing queries, the sub-resource groups obtain resources in turn based on the defined sequence. The query of the same sub-resource group obtains resources based on the first-come-first-executed rule.
The schedulingWeight attribute is configured for each resource group that uses this policy. Each sub-resource group calculates a ratio: Number of queried sub-resource groups/Scheduling weight. A sub-resource group with a smaller ratio obtains resources first.
The default value is 1. A larger value of schedulingWeight indicates that resources are obtained earlier.
All sub-resource groups must be set with query_priority. Resources are obtained in the sequence specified by query_priority. |
schedulingWeight | No | Weight of the group. For details, see schedulingPolicy. The default value is 1. |
jmxExport | No | If this parameter is set to true, group statistics are exported to the JMX for monitoring. The default value is false. |
subGroups | No | Subgroup list |
Selector Rules¶
The selector matches resource groups in sequence. The first matched resource group is used. Generally, you are advised to configure a default resource group. If no default resource group is configured and other resource group selector conditions are not met, the query will be rejected. For details about how to set selector rule parameters, see Table 3.
Configuration Item | Mandatory | Description |
|---|---|---|
user | No | Regular expression for matching the user name. |
source | No | Data source to be matched with, such as JDBC, HBase, and Hive. For details, see the value of --source in Configuration of Selector Attributes. |
queryType | No | Task types:
|
clientTags | No | Match client tag to be matched with. Each tag must be in the tag list of the task submitted by the user. For details, see the value of --client-tags in Configuration of Selector Attributes. |
group | Yes | The resource group with running queries |
Global Attributes¶
For details about how to configure global attributes, see Table 4.
Configuration Item | Mandatory | Description |
|---|---|---|
cpuQuotaPeriod | No | Time range during which the CPU quota takes effect. This parameter is used together with softCpuLimit and hardCpuLimit in Resource Group Properties. |
Configuration of Selector Attributes¶
The data source name (source) can be set as follows:
CLI: Use the --source option.
JDBC: Set the ApplicationName client information property on the Connection instance.
The client tag (clientTags) can be configured as follows:
CLI: Use the --client-tags option.
JDBC: Set the ClientTags client info property on the Connection instance.
Configuration Example¶
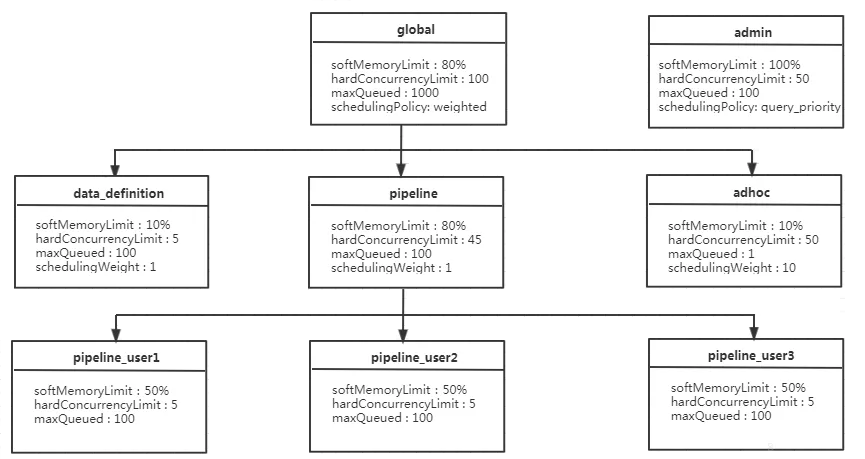
Figure 1 Configuration example¶
As shown in Figure 1.
For the global resource group, a maximum of 100 queries can be executed at the same time. 1000 queries are in the queuing state. The global resource group has three sub-resource groups: data_definition, adhoc, and pipeline.
Each user in the pipeline resource group can run a maximum of five queries at the same time, which occupy 50% of the memory resources of the pipeline resource group. By default, the fair scheduling policy is used in the pipeline resource group. Therefore, the query is executed in the sequence of "first come, first served".
To make full use of instance resources, the total memory quota of all child resource groups can be greater than that of the parent resource group. For example, the sum of the memory quota of the global resource group (80%) and that of the admin resource group (100%) is 180%, which is greater than 100%.
In the following example configuration, there are multiple resource groups, some of which are templates. HetuEngine administrators can use templates to dynamically build a resource group tree. For example, in the pipeline_${USER} group, ${USER} is the name of the user who submits a query. ${SOURCE} is also supported, which will be the source where a query is submitted later. You can also use custom variables in source expressions and user regular expressions.
The following is an example of a resource group selector:
"selectors": [{
"user": "bob",
"group": "admin"
},
{
"source": ".*pipeline.*",
"queryType": "DATA_DEFINITION",
"group": "global.data_definition"
},
{
"source": ".*pipeline.*",
"group": "global.pipeline.pipeline_${USER}"
},
{
"source": "jdbc#(?<toolname>.*)",
"clientTags": ["hipri"],
"group": "global.adhoc.bi-${toolname}.${USER}"
},
{
"group": "global.adhoc.other.${USER}"
}]
There are four selectors that define which resource group to run the query:
The first selector matches queries from bob and places them in the admin group.
The second selector matches all data definition language (DDL) queries from the source name that includes the pipeline and places them in the global.data_definition group. This helps reduce the queuing time of such queries.
The third selector matches queries from sources that include the pipeline and places them in a single-user pipe group that is dynamically created under the global.pipeline group.
The fourth selector matches queries from BI tools whose sources match the regular expression jdbc#(?<toolname>.*), and the tags provided by the client are the superset of hi-pri. These files are placed in the subgroups that are dynamically created under the global.pipeline.tools group. Dynamic subgroups are created based on the naming variable toolname, which is extracted from the source regular expression. Consider queries that use the query containing the source jdbc#powerfulbi, user kayla, and client tags, hipri and fast. This query will be routed to the global.pipeline.bi-powerfulbi.kayla resource group.
The last selector is a default selector that puts all the unmatched queries into the resource group.
These selectors work together to implement the following policies:
HetuEngine administrator bob can run 50 queries at the same time. The query will run according to the user-supplied priority.
For the remaining users:
The total number of concurrent queries cannot exceed 100.
You can use the source pipeline to run a maximum of five concurrent DDL queries. The query is performed in the FIFO sequence.
Non-DDL queries are executed in the global.pipeline group. The total number of concurrent queries is 45, and each user can run 5 queries concurrently. The query is performed in the FIFO sequence.
Each BI tool can run a maximum of 10 concurrent queries, and each user can run a maximum of three concurrent queries. If the total number of concurrent queries exceeds 10, the user who runs the least queries gets the next concurrency slot. This policy makes it fairer to compete for resources.
All the remaining queries are placed in each of the user groups under global.adhoc.other.
The description of the query match selector is as follows:
Each pair of braces represents a selector that matches the resource group. Five selectors are configured to match the five resource groups.
admin global.data_definition global.pipeline.pipeline_${USER} global.adhoc.bi-${toolname}.${USER global.adhoc.other.${USER}Only when all the conditions of the selector are met, the task can be put into the current queue for execution. For example, if user amy submits a query request in JDBC mode and clientTags is not configured, the query request cannot be allocated to the resource group global.adhoc.bi-${toolname}.${USER}.
When a query can meet the conditions of two selectors at the same time, the first selector that meets the requirements is matched. For example, if the bob user submits a DATA_DEFINITION job whose source is pipeline, only the resource corresponding to the resource group admin is matched, not the resource corresponding to global.data_definition.
If none of the four selectors is matched, resources in the resource group global.adhoc.other.${USER} specified by the last selector are used. This resource group functions as a default resource group. If the default resource group is not set and does not meet the conditions of other resource group selectors, the resource group will be rejected.
The following is a complete example:
{ "rootGroups": [{ "name": "global", "softMemoryLimit": "80%", "hardConcurrencyLimit": 100, "maxQueued": 1000, "schedulingPolicy": "weighted", "jmxExport": true, "subGroups": [{ "name": "data_definition", "softMemoryLimit": "10%", "hardConcurrencyLimit": 5, "maxQueued": 100, "schedulingWeight": 1 }, { "name": "adhoc", "softMemoryLimit": "10%", "hardConcurrencyLimit": 50, "maxQueued": 1, "schedulingWeight": 10, "subGroups": [{ "name": "other", "softMemoryLimit": "10%", "hardConcurrencyLimit": 2, "maxQueued": 1, "schedulingWeight": 10, "schedulingPolicy": "weighted_fair", "subGroups": [{ "name": "${USER}", "softMemoryLimit": "10%", "hardConcurrencyLimit": 1, "maxQueued": 100 }] }, { "name": "bi-${toolname}", "softMemoryLimit": "10%", "hardConcurrencyLimit": 10, "maxQueued": 100, "schedulingWeight": 10, "schedulingPolicy": "weighted_fair", "subGroups": [{ "name": "${USER}", "softMemoryLimit": "10%", "hardConcurrencyLimit": 3, "maxQueued": 10 }] }] }, { "name": "pipeline", "softMemoryLimit": "80%", "hardConcurrencyLimit": 45, "maxQueued": 100, "schedulingWeight": 1, "jmxExport": true, "subGroups": [{ "name": "pipeline_${USER}", "softMemoryLimit": "50%", "hardConcurrencyLimit": 5, "maxQueued": 100 }] }] }, { "name": "admin", "softMemoryLimit": "100%", "hardConcurrencyLimit": 50, "maxQueued": 100, "schedulingPolicy": "query_priority", "jmxExport": true }], "selectors": [{ "user": "bob", "group": "admin" }, { "source": ".*pipeline.*", "queryType": "DATA_DEFINITION", "group": "global.data_definition" }, { "source": ".*pipeline.*", "group": "global.pipeline.pipeline_${USER}" }, { "source": "jdbc#(?<toolname>.*)", "clientTags": ["hipri"], "group": "global.adhoc.bi-${toolname}.${USER}" }, { "group": "global.adhoc.other.${USER}" }], "cpuQuotaPeriod": "1h" }