Connecting Flume with Hive in Security Mode¶
Scenario¶
This section describes how to use Flume to connect to Hive (version 3.1.0) in the cluster.
Prerequisites¶
Flume and Hive have been correctly installed in the cluster. The services are running properly, and no alarm is reported.
Procedure¶
Import the following JAR packages to the lib directory (client/server) of the Flume instance to be tested as user omm:
antlr-2.7.7.jar
antlr-runtime-3.4.jar
calcite-core-1.16.0.jar
hadoop-mapreduce-client-core-3.1.1.jar
hive-beeline-3.1.0.jar
hive-cli-3.1.0.jar
hive-common-3.1.0.jar
hive-exec-3.1.0.jar
hive-hcatalog-core-3.1.0.jar
hive-hcatalog-pig-adapter-3.1.0.jar
hive-hcatalog-server-extensions-3.1.0.jar
hive-hcatalog-streaming-3.1.0.jar
hive-metastore-3.1.0.jar
hive-service-3.1.0.jar
libfb303-0.9.3.jar
hadoop-plugins-1.0.jar
You can obtain the JAR package from the Hive installation directory and restart the Flume process to ensure that the JAR package is loaded to the running environment.
Set Hive configuration items.
On FusionInsight Manager, choose Cluster > Name of the desired cluster > Services > Hive > Configurations > All Configurations > HiveServer > Customization > hive.server.customized.configs.
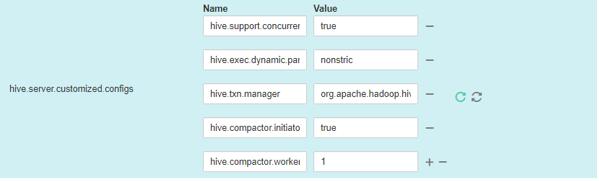
Example configurations:
Name
Value
hive.support.concurrency
true
hive.exec.dynamic.partition.mode
nonstrict
hive.txn.manager
org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
hive.compactor.initiator.on
true
hive.compactor.worker.threads
1
Prepare the system user flume_hive who has the supergroup and Hive permissions, install the client, and create the required Hive table.
Example:
The cluster client has been correctly installed. For example, the installation directory is /opt/client.
Run the following command to authenticate the user:
cd /opt/client
source bigdata_env
kinit flume_hive
Run the beeline command and run the following table creation statement:
create table flume_multi_type_part(id string, msg string) partitioned by (country string, year_month string, day string) clustered by (id) into 5 buckets stored as orc TBLPROPERTIES('transactional'='true');
Run the select * from Table name; command to query data in the table.
In this case, the number of data records in the table is 0.
Prepare related configuration files. Assume that the client installation package is stored in /opt/FusionInsight_Cluster_1_Services_ClientConfig.
Obtain the following files from the $Client decompression directory/Hive/config directory:
hivemetastore-site.xml
hive-site.xml
Obtain the following files from the $Client decompression directory/HDFS/config directory:
core-site.xml
Create a directory on the host where the Flume instance is started and save the prepared files to the created directory.
Example: /opt/hivesink-conf/hive-site.xml.
Copy all property configurations in the hivemetastore-site.xml file to the hive-site.xml file and ensure that the configurations are placed before the original configurations.
Data is loaded in sequence in Hive.
Note
Ensure that the Flume running user omm has the read and write permissions on the directory where the configuration file is stored.
Observe the result.
On the Hive client, run the select * from Table name; command. Check whether the corresponding data has been written to the Hive table.
Examples¶
Flume configuration example (SpoolDir--Mem--Hive):
server.sources = spool_source
server.channels = mem_channel
server.sinks = Hive_Sink
#config the source
server.sources.spool_source.type = spooldir
server.sources.spool_source.spoolDir = /tmp/testflume
server.sources.spool_source.montime =
server.sources.spool_source.fileSuffix =.COMPLETED
server.sources.spool_source.deletePolicy = never
server.sources.spool_source.trackerDir =.flumespool
server.sources.spool_source.ignorePattern = ^$
server.sources.spool_source.batchSize = 20
server.sources.spool_source.inputCharset =UTF-8
server.sources.spool_source.selector.type = replicating
server.sources.spool_source.fileHeader = false
server.sources.spool_source.fileHeaderKey = file
server.sources.spool_source.basenameHeaderKey= basename
server.sources.spool_source.deserializer = LINE
server.sources.spool_source.deserializer.maxBatchLine= 1
server.sources.spool_source.deserializer.maxLineLength= 2048
server.sources.spool_source.channels = mem_channel
#config the channel
server.channels.mem_channel.type = memory
server.channels.mem_channel.capacity =10000
server.channels.mem_channel.transactionCapacity= 2000
server.channels.mem_channel.channelfullcount= 10
server.channels.mem_channel.keep-alive = 3
server.channels.mem_channel.byteCapacity =
server.channels.mem_channel.byteCapacityBufferPercentage= 20
#config the sink
server.sinks.Hive_Sink.type = hive
server.sinks.Hive_Sink.channel = mem_channel
server.sinks.Hive_Sink.hive.metastore = thrift://${any MetaStore service IP address}:21088
server.sinks.Hive_Sink.hive.hiveSite = /opt/hivesink-conf/hive-site.xml
server.sinks.Hive_Sink.hive.coreSite = /opt/hivesink-conf/core-site.xml
server.sinks.Hive_Sink.hive.metastoreSite = /opt/hivesink-conf/hivemeatastore-site.xml
server.sinks.Hive_Sink.hive.database = default
server.sinks.Hive_Sink.hive.table = flume_multi_type_part
server.sinks.Hive_Sink.hive.partition = Tag,%Y-%m,%d
server.sinks.Hive_Sink.hive.txnsPerBatchAsk= 100
server.sinks.Hive_Sink.hive.autoCreatePartitions= true
server.sinks.Hive_Sink.useLocalTimeStamp = true
server.sinks.Hive_Sink.batchSize = 1000
server.sinks.Hive_Sink.hive.kerberosPrincipal= super1
server.sinks.Hive_Sink.hive.kerberosKeytab= /opt/mykeytab/user.keytab
server.sinks.Hive_Sink.round = true
server.sinks.Hive_Sink.roundValue = 10
server.sinks.Hive_Sink.roundUnit = minute
server.sinks.Hive_Sink.serializer = DELIMITED
server.sinks.Hive_Sink.serializer.delimiter= ";"
server.sinks.Hive_Sink.serializer.serdeSeparator= ';'
server.sinks.Hive_Sink.serializer.fieldnames= id,msg