Disaster Recovery and Multi-Active Solution¶
Whether you use DCS as the frontend cache or backend data store, DCS is always ready to ensure data reliability and service availability. The following figure shows the evolution of DCS DR architectures.
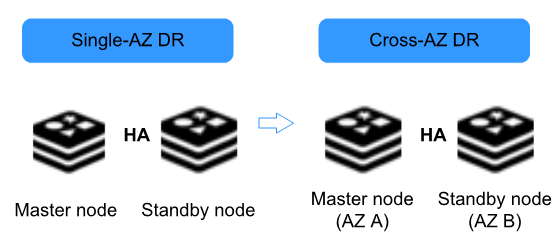
Figure 1 DCS DR architecture evolution¶
To meet the reliability requirements of your data and services, you can choose to deploy your DCS instance within a single AZ or across AZs.
Single-AZ HA¶
Single-AZ deployment means to deploy an instance within a physical equipment room. DCS provides process/service HA, data persistence, and hot standby DR policies for different types of DCS instances.
Single-node DCS instance: When DCS detects a process fault, a new process is started to ensure service HA.
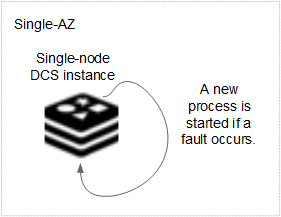
Figure 2 HA for a single-node DCS instance deployed within an AZ¶
By default, instances except for single-node ones support data persistence. Data is persisted to disk in the master node and incrementally synchronized and persisted to the standby node, achieving hot standby and persistent data backups.
For master/standby or read/write splitting instances, and each shard of cluster instances, the master node process synchronizes and persists data to the standby node processes, as shown in the following figure.
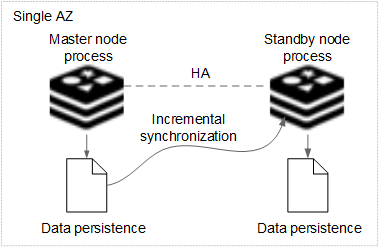
Figure 3 HA for a master/standby DCS instance deployed within an AZ¶
Cross-AZ DR¶
The master and standby nodes of a master/standby, read/write splitting, or cluster DCS instance can be deployed across AZs (in different equipment rooms). Power supplies and networks of different AZs are physically isolated. When a fault occurs in the AZ where the master node is deployed, the standby node connects to the client and takes over data read and write operations.
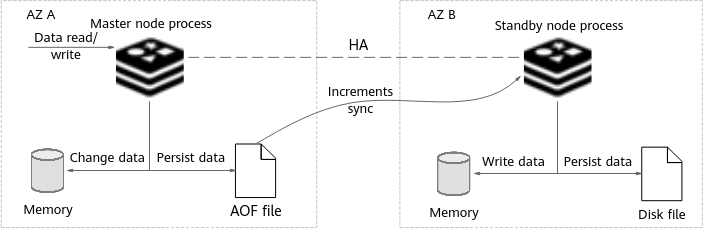
Figure 4 Cross-AZ deployment of a master/standby DCS instance¶
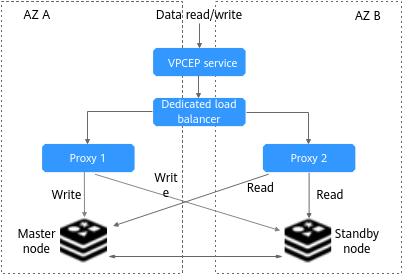
Figure 5 Cross-AZ deployment of a read/write splitting DCS instance¶
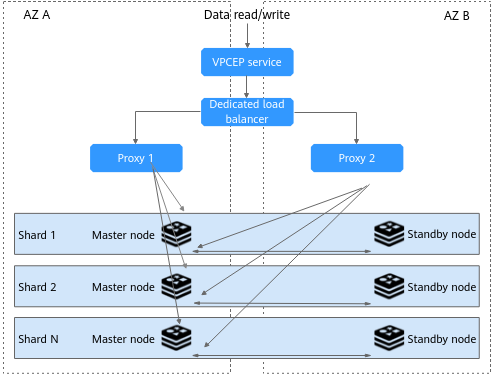
Figure 6 Cross-AZ deployment of a Proxy Cluster DCS instance¶
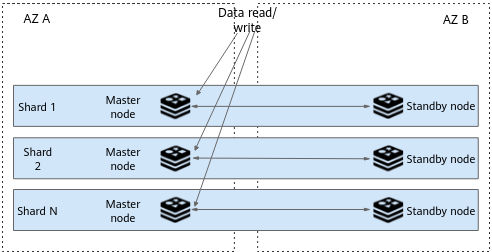
Figure 7 Cross-AZ deployment of a Redis Cluster DCS instance¶
When creating a master/standby, read/write splitting, or cluster DCS instance, select a standby AZ that is different from the primary AZ.
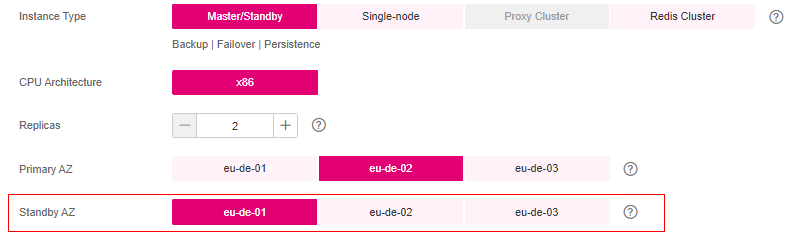
Figure 8 Selecting different AZs¶
Note
You can deploy your application across AZs to ensure both data reliability and service availability in the event of power supply or network disruptions.
Cross-AZ instances do not support password changes, command renaming, and specification modification when an AZ is faulty.