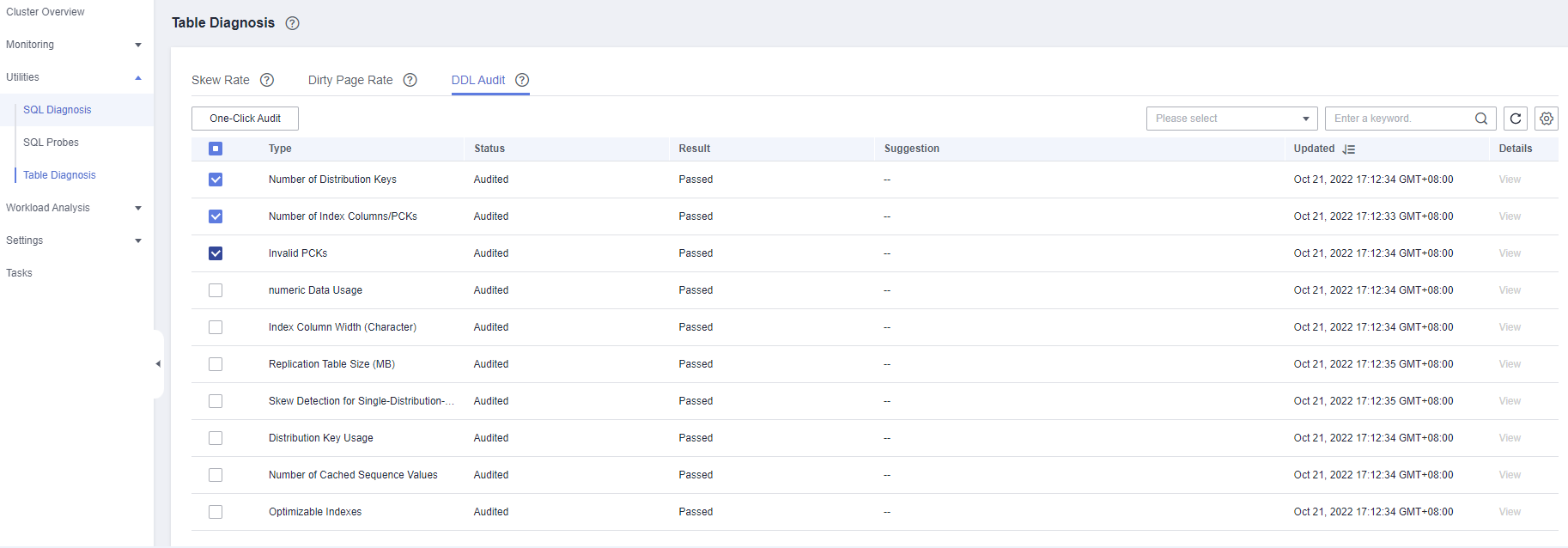
Table Diagnosis¶
GaussDB(DWS) provides statistics and diagnostic tools for you to learn table status, including:
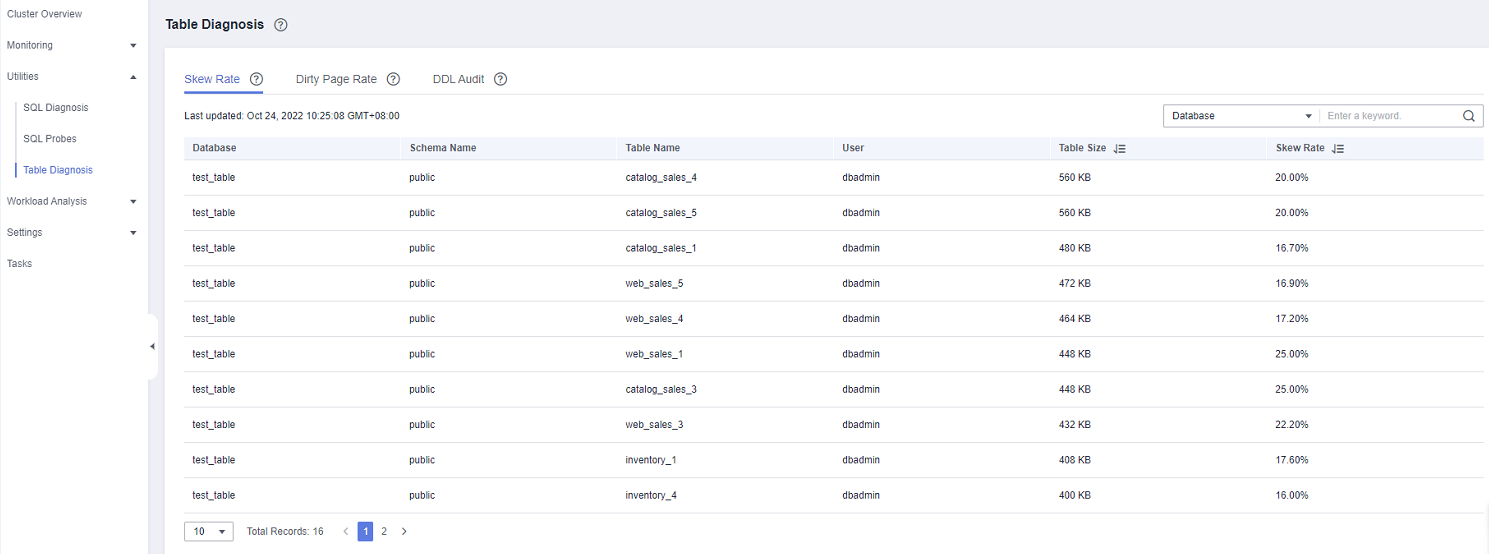
Skew Rate: monitors and analyzes data table statistics in the cluster, and displays information about the 50 largest tables whose skew rate is higher than 5%.
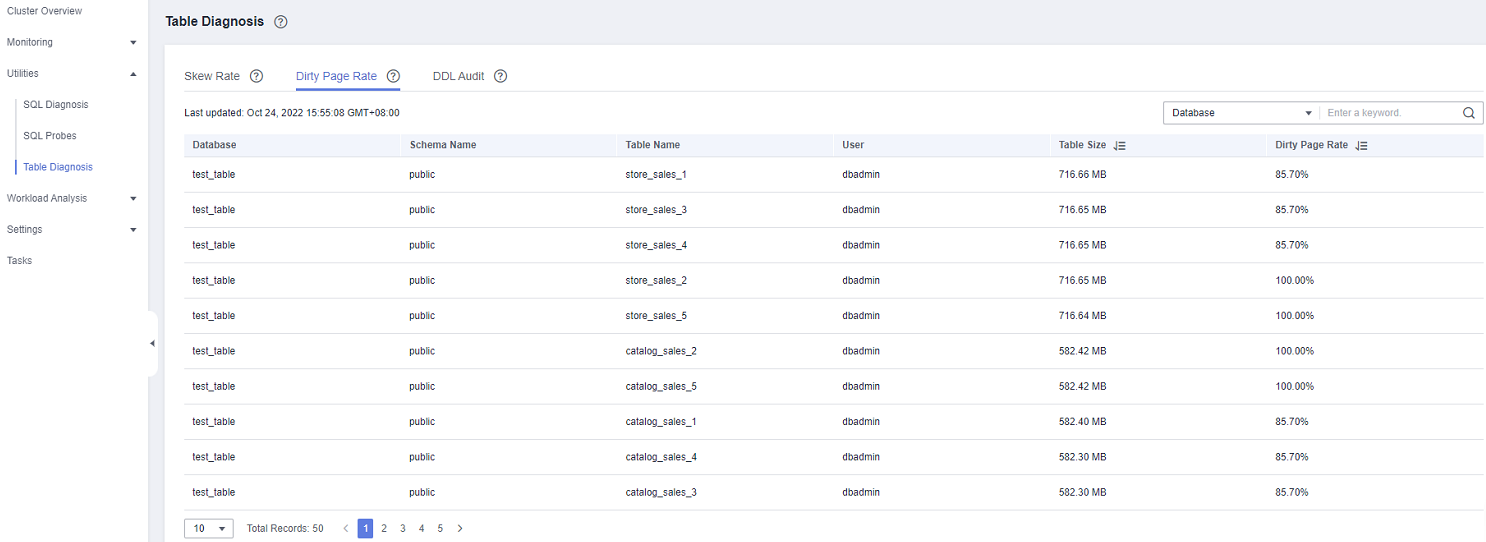
Dirty Page Rate: monitors and analyzes data table statistics in the cluster, and displays information about the 50 largest tables whose skew rate is higher than 50%.
DDL Audit: DDL review is a type of SQL review. To prevent improper DDL design from affecting services, this tool checks whether DDL metadata is standard, detecting potential table definition problems in advance. The check result can also be used as a reference for locating performance issues.
Note
Only 8.1.1.x and later versions support the table skew rate and dirty page rate features. For earlier versions, contact technical support.
Only 8.1.1.300 and later versions support the DDL review feature. For earlier versions, contact technical support.
The data collection period of the table skew and dirty page checks can be configured on the Monitoring Collection page. Frequent data collection may affect cluster performance. Set a proper period based on your cluster workloads.
Skew Rate¶
Context
Improper distribution columns can cause severe skew during operator computing or data spill to disk. The workloads will be unevenly distributed on DNs, resulting in high disk usage on a single DN and affecting performance. You can query the table skew rate and then choose an alternative distribution column for the table with significant skew. Consider both the table size and the skew rate when making your selection. For clusters of 8.1.0 or later, see section "ALTR TABLE" in Data Warehouse Service (DWS) Developer Guide. For other versions, see "How Do I Adjust Distribution Columns?" in Data Warehouse Service (DWS) User Guide
Procedure
Log in to the GaussDB(DWS) management console.
On the Clusters > Dedicated Clusters page, locate the cluster to be monitored.
In the Operation column of the target cluster, click Monitoring Panel.
In the navigation tree on the left, choose Utilities > Table Diagnosis and click the Skew Rate tab. The tables that meet the statistics collection conditions in the cluster are displayed.
Dirty Page Rate¶
Context
DML operations on tables may generate dirty data, which unnecessarily occupies cluster storage. You can query the dirty page rate, and handle large tables and tables with high dirty page rate. For details, see "Solution to High Disk Usage and Cluster Read-Only" in Data Warehouse Service (DWS) User Guide.
Procedure
Log in to the GaussDB(DWS) management console.
On the Clusters > Dedicated Clusters page, locate the cluster to be monitored.
In the Operation column of the target cluster, click Monitoring Panel.
In the navigation tree on the left, choose Utilities > Table Diagnosis and click the Dirty Page Rate tab. The tables that meet the statistics collection conditions in the cluster are displayed.
DDL Audit¶
Viewing and Exporting DDL Audit Results
Log in to the GaussDB(DWS) management console.
On the Clusters > Dedicated Clusters page, locate the cluster to be monitored.
In the Operation column of the target cluster, click Monitoring Panel.
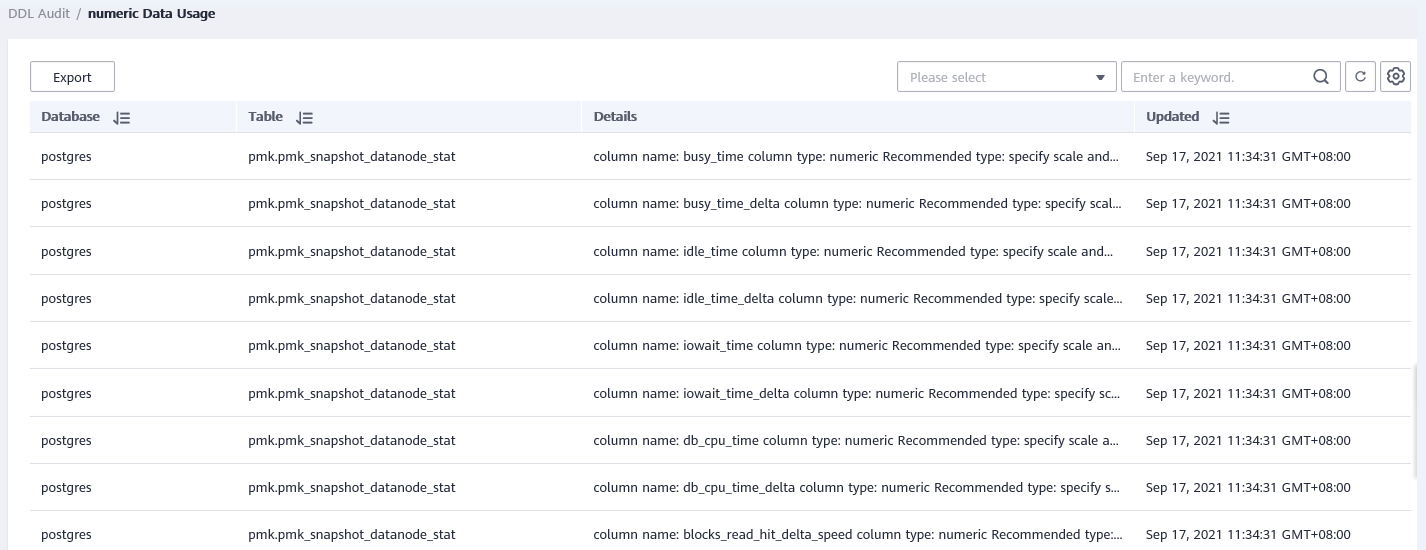
In the navigation tree on the left, choose Utilities > Table Diagnosis, and click the DDL Audit tab. The audit results are displayed.
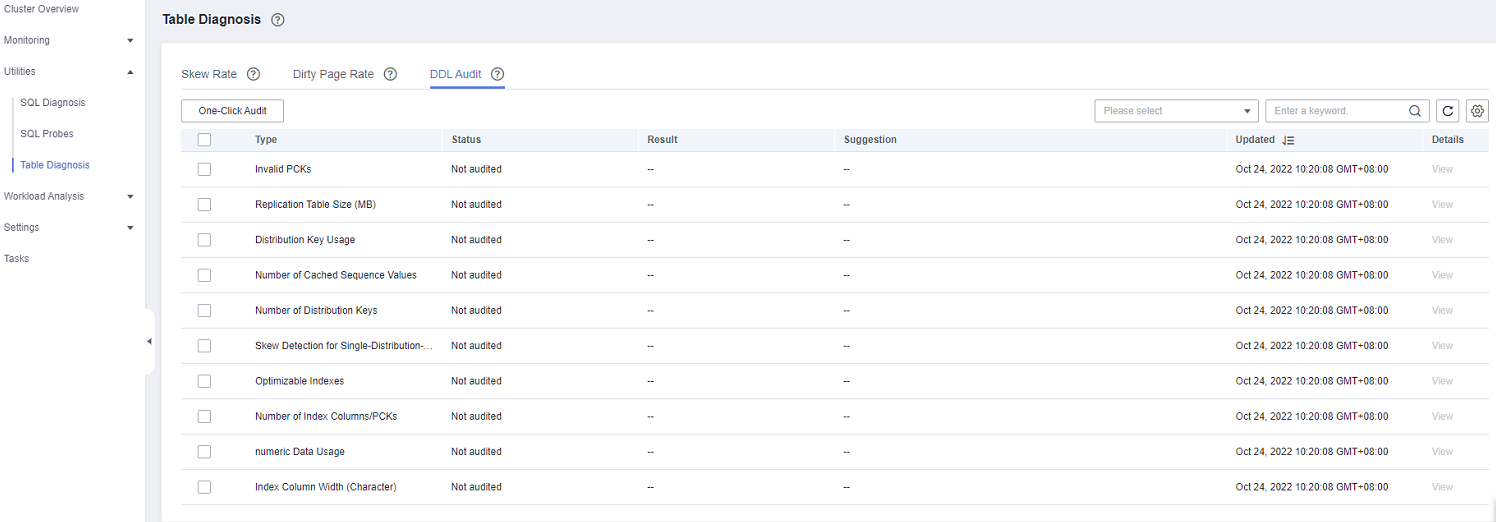
Note
The selected audit items are displayed on the DDL Audit tab by default. You can configure the audit items on the Monitoring Collection tab. For more information, see Table 1.
Table 1 Audit items¶ Item
Description
Number of Distribution Keys (disKeyCount)
If there is no data skew, use no more than four distribution keys.
Generally, if you use many distribution keys, data can be evenly distributed in a cluster, thus avoid data skew. However, if too many distribution keys are used, the storage performance and joint query performance may deteriorate. You are advised to configure no more than four distribution keys.
Storage performance issue:
When data is added, the hash function calculates the result of each distribution column, aggregates the results, and then determine where to distribute data. A large number of distribution keys require time-consuming, complex calculation.
Union query performance issue:
During multi-table join query, if all the columns of the distribution key are involved in the join condition, data does not need to be redistributed in the execution plan. If a large number of distribution keys are used, some of them may not be the columns involved in the join condition, and data redistribution may occur, which consumes many resources and takes long.
Number of Index Columns/PCKs (indexKeyOrPckCount)
It is recommended that the number of partial cluster keys (PCKs)/columns of an index be less than or equal to 4.
A large number of index columns require many resources to maintain index data, and are likely to contain duplicate indexes.
While column-store data is imported, PCK columns are compared and calculated to determine CU division. A large number of PCKs will consume many resources and much time, affecting performance. To efficiently filter CUs in a query, the prefixes of the columns involved in the query conditions must be PCK columns. and b>? (For example, if the PCK columns are a, b, and c, the query criteria must be a>? and b>? and c>?.) Otherwise, all the CUs must be traversed, and data clustering does not contribute to query acceleration.
Invalid PCKs (invalidPck)
Do not create invalid PCK columns.
In 8.1.1 and later versions, the cluster can filter and compare data of the char, int8, int2, int4, text, bpchar, varchar, date, time, timestamp and timestamptz types. If a column of an unsupported data type is used as a PCK, the column is an invalid PCK column. It does not take effect during CU filtering and will consume resources for its maintenance.
numeric Data Usage (validityOfNumeric)
When numeric data types are used, use integers if possible. If the precision requirement is not high, use the float fixed-length data type. The float fixed-length data type has better computing performance than the numeric variable-length data type.
That is, if the numeric type is used, you are advised to specify the scale and precision within 38 bits. When the numeric type is used for calculation, the underlying layer attempts to convert the calculation to the calculation between int and bigint to improve the calculation efficiency. That is, the large integer optimization of the data type is used.
In 8.1.1 and later versions, if no precision is specified, a maximum of 131,072 digits can be placed before the decimal point and a maximum of 16,383 digits can be placed after the decimal point. That is, the maximum scale and precision are used. In this case, large integer optimization cannot be performed during calculation, and the calculation efficiency decreases accordingly.
Index Column Width (widthOfIndexKey)
Generally, wide index columns are character string columns, which do not involve compare operations and will lead to large indexes that consume unnecessary space. Specify a value smaller than 64 bytes.
Replication Table Size (sizeOfCopyTable)
Tables that occupy more storage space than the threshold (100 MB) on a single DN will be identified. For such tables, you are advised to use common associated columns as distribution keys (generally with one primary key).
The cluster supports replication tables. A replication table maintains a full copy of data on each node and is mainly used to store data of enumerated types. If a table contains too much data, it will occupy a large amount of space. In addition, in a union query, the node traverses all table data, which may take a longer time than the union query after the table type is changed to distribution table. (Although data may be redistributed in the distribution table, the amount of data traversed by each node decreases.)
Skew Detection for Single-Distribution-Key Tables (recognitionOfDataSkew)
Data skew of single-distribution-key tables is detected by statistics. This audit applies only to tables with one distribution key.
Distribution Key Usage (validityOfDiskey)
In a cluster, you are not advised to use a column of the Boolean or date type as a distribution column, because it may cause data skew.
Number of Cached Sequence Values (cacheSizeOfSequence)
Specify a number greater than 100.
If a table column uses sequences, its next_value is obtained from the cached value in the local node. If cached sequence values are used up, a request will be sent asking GTM to obtain the value again. If a large amount of data is added but only a few values are cached, GTM will receive many requests, and may get overloaded and even break down. To avoid this problem, you are advised to set the cache value to a value greater than 100 when creating a sequence.
Optimizable Indexes (optimizableIndexKey)
Scenarios where indexes can be optimized:
The index column of an index is the first N columns of another index.
The index columns of two indexes are the same, but the orders are different.
If the review result of an item is Failed, click View to go to the details page.
Click Export in the upper left corner to export the audit result.
Manually Auditing DDL Items
Log in to the GaussDB(DWS) management console.
On the Clusters > Dedicated Clusters page, locate the cluster to be monitored.
In the Operation column of the target cluster, choose Monitoring Panel. The database monitoring page is displayed.
In the navigation tree on the left, choose Utilities > Table Diagnosis, and click the DDL Audit tab. On the page that is displayed, select the items to be audited and click One-Click Audit.