How Do I Change Distribution Columns?¶
In a data warehouse database, you need to carefully choose distribution columns for large tables, because they can affect your database and query performance. If an improper distribution key is used, data skew may occur after data is imported. As a result, the usage of some disks will be much higher than that of other disks, and the cluster may even become read-only. If the hash distribution policy is used and data skew occurs, the I/O performance of some DNs will be poor, affecting the overall query performance. Proper selection and adjustment of distribution columns are critical to table query performance.
If the hash distribution policy is used, you need to check tables to ensure their data is evenly distributed on each DN. Generally, over 5% difference between the amount of data on different DNs is regarded as data skew. If the difference is over 10%, you have to choose another distribution column.
For tables that are not evenly distributed, adjust their distribution columns to reduce data skew and avoid database performance problems.
Choosing an Appropriate Distribution Column¶
The distribution column in a hash table must meet the following requirements, which are ranked by priority in descending order:
The values of the distribution key should be discrete so that data can be evenly distributed on each DN. You can select the primary key of the table as the distribution key. For example, for a person information table, choose the ID card number column as the distribution key.
Do not select the column where a constant filter exists.
Select the join condition as the distribution column, so that join tasks can be pushed down to DNs to execute, reducing the amount of data transferred between the DNs.
Multiple distribution columns can be selected to evenly distribute data.
Procedure¶
Run the select version(); statement to query the current database version. Required performance varies according to the version.

For 8.0.x and earlier versions, specify the distribution column when rebuilding a table.
Use Data Studio or gsql in Linux to access the database.
Create a table.
Note
In the following statements, table1 is the original table name and table1_new is the new table name. column1 and column2 are distribution column names.
CREATE TABLE IF NOT EXISTS table1_new ( LIKE table1 INCLUDING ALL EXCLUDING DISTRIBUTION) DISTRIBUTE BY HASH (column1, column2);
Migrate data to the new table.
START TRANSACTION; LOCK TABLE table1 IN ACCESS EXCLUSIVE MODE; INSERT INTO table1_new SELECT * FROM table1; COMMIT;
Verify that the table data has been migrated. Delete the original table.
SELECT COUNT(*) FROM table1_new; DROP TABLE table1;
Replace the original table.
ALTER TABLE table1_new RENAME TO table1;
In 8.1.0 and later versions, you can use the ALTER TABLE syntax. For example:
Query the table definition. The command output shows that the distribution column of the table is c_last_name.
SELECT pg_get_tabledef('customer_t1');
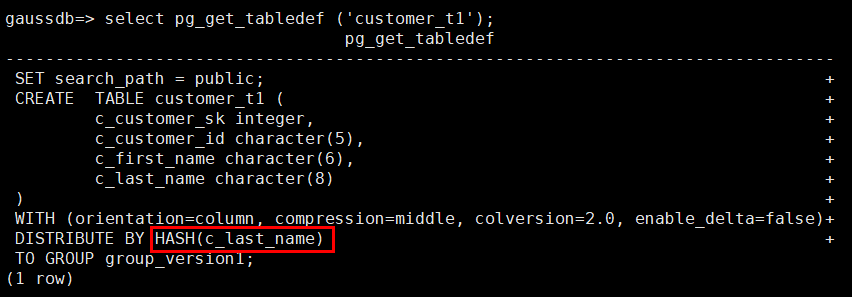
Try updating data in the distribution column. An error message will be displayed.
UPDATE customer_t1 SET c_last_name = 'Jimy' WHERE c_customer_sk = 6885;

Change the distribution column of the table to a column that cannot be updated, for example, c_customer_sk.
ALTER TABLE customer_t1 DISTRIBUTE BY hash (c_customer_sk);

Update the data in the old distribution column.
UPDATE customer_t1 SET c_last_name = 'Jimy'WHERE c_customer_sk = 6885;
