Reviewing and Modifying a Table Definition¶
In a distributed framework, data is distributed on DNs. Data on one or more DNs is stored on a physical storage device. To properly define a table, you must:
Evenly distribute data on each DN to avoid the available capacity decrease of a cluster caused by insufficient storage space of the storage device associated with a DN. Specifically, select a proper distribution key to avoid data skew.
Evenly assign table scanning tasks on each DN to avoid that a DN is overloaded by the table scanning tasks. Specifically, do not select columns in the equivalent filter of a base table as the distribution key.
Reduce the data volume scanned by using the partition pruning mechanism.
Avoid the use of random I/O by using clustering or partial clustering.
Avoid data shuffle to reduce the network pressure by selecting the join-condition column or group by column as the distribution column.
The distribution column is the core for defining a table. The following figure shows the procedure of defining a table. The table definition is created during the database design and is reviewed and modified during the SQL statement optimization.
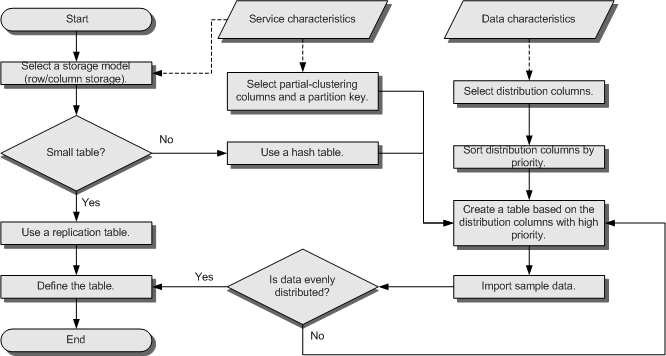
Figure 1 Procedure of defining a table¶