Case: Selecting an Appropriate Distribution Column¶
Distribution columns are used to distribute data to different nodes. A proper distribution key can avoid data skew.
When performing join query, you are advised to select the join condition in the query as the distribution key. When a join condition is used as a distribution key, related data is distributed locally on DNs, reducing the cost of data flow between DNs and improving the query speed.
Before optimization¶
Use a as the distribution column of t1 and t2. The table definition is as follows:
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a);
CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (a);
The following query is executed:
SELECT * FROM t1, t2 WHERE t1.a = t2.b;
In this case, the execution plan contains Streaming(type: REDISTRIBUTE), that is, the DN redistributes data to all DNs based on the selected column. This will cause a large amount of data to be transmitted between DNs, as shown in Figure 1.
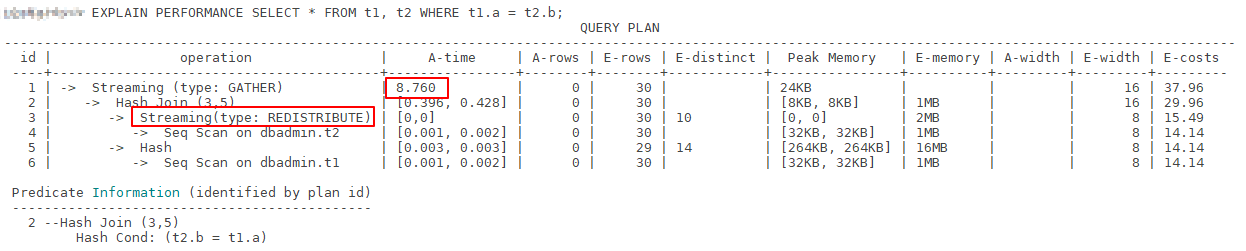
Figure 1 Selecting an appropriate distribution column (1)¶
After optimization¶
Use the join condition in the query as the distribution key and run the following statement to changethe distribution key of t2 as b:
ALTER TABLE t2 DISTRIBUTE BY HASH (b);
After the distribution column of table t2 is changed to column b, the execution plan does not contain Streaming(type: REDISTRIBUTE). This reduces the amount of communication data between DNs and reduces the execution time from 8.7 ms to 2.7 ms, improving query performance, as shown in Figure 2.

Figure 2 Selecting an appropriate distribution column (2)¶