Migrating Data from MySQL to DWS¶
Scenario¶
CDM supports table-to-table data migration. This section describes how to migrate data from MySQL to DWS. The process is as follows:
Prerequisites¶
You have obtained the IP address, port number, database name, username, and password for connecting to DWS. In addition, you must have the read, write, and delete permissions on the DWS database.
You have obtained the IP address, port, database name, username, and password for connecting to the MySQL database. In addition, the user must have the read and write permissions on the MySQL database.
You have uploaded the MySQL database driver on the Job Management > Links > Driver Management page.
Creating a CDM Cluster and Binding an EIP to the Cluster¶
Create a CDM cluster.
The key configurations are as follows:
The flavor of the CDM cluster is selected based on the amount of data to be migrated. Generally, cdm.medium meets the requirements for most migration scenarios.
The VPC, subnet, and security group of the CDM cluster must be the same as those of the DWS cluster.
After the CDM cluster is created, on the Cluster Management page, click Bind EIP in the Operation column to bind an EIP to the cluster. The CDM cluster uses the EIP to access MySQL.
Note
If SSL encryption is configured for the access channel of a local data source, CDM cannot connect to the data source using the EIP.
Creating a MySQL Link¶
On the Cluster Management page, locate a cluster and click Job Management in the Operation column. On the displayed page, click the Links tab and then Create Link.
Select RDS for MySQL and click Next to set the link parameters.
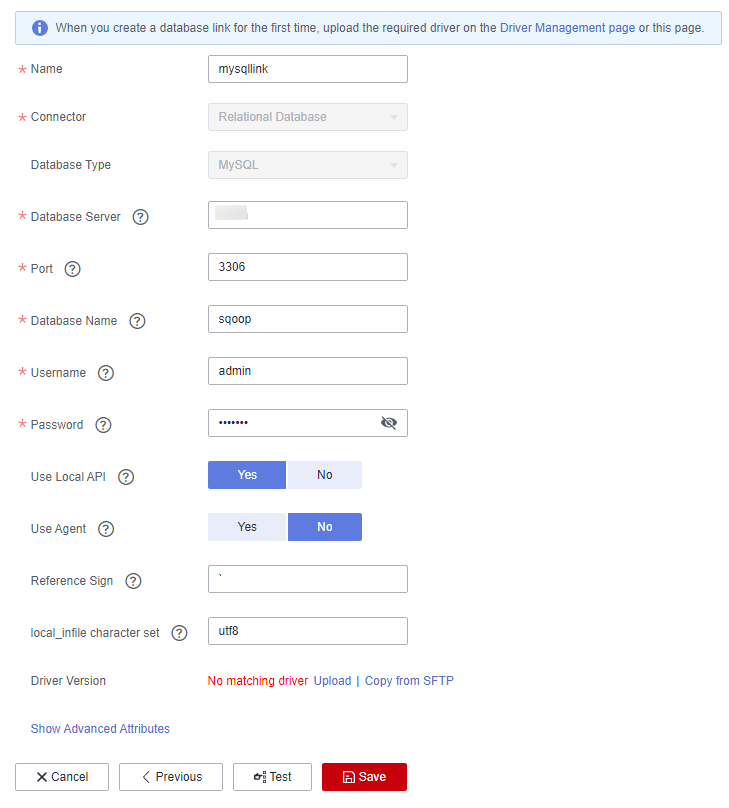
Figure 1 Creating a MySQL link¶
Click Show Advanced Attributes to view more optional parameters. For details, see Link to an RDS for MySQL/MySQL Database. Retain the default values of the optional parameters and configure the mandatory parameters according to Table 1.
Table 1 MySQL link parameters¶ Parameter
Description
Example Value
Name
Unique link name
mysqllink
Database Server
IP address or domain name of the MySQL database server
-Port
MySQL database port
3306
Database Name
Name of the MySQL database
sqoop
Username
User who has the read, write, and delete permissions on the MySQL database
admin
Password
Password of the user
-Use Local API
Whether to use the local API of the database for acceleration. (The system attempts to enable the local_infile system variable of the MySQL database.)
Yes
Use Agent
Whether to extract data from the data source through an agent
No
local_infile Character Set
When using local_infile to import data to MySQL, you can configure the encoding format.
utf8
Driver Version
Before connecting CDM to a relational database, you need to upload the JDK 8 .jar driver of the relational database. Download the MySQL driver 5.1.48 from https://downloads.mysql.com/archives/c-j/, obtain mysql-connector-java-5.1.48.jar, and upload it.
-Click Save. The Link Management page is displayed.
Note
If an error occurs during the saving, the security settings of the MySQL database are incorrect. In this case, you need to enable the EIP of the CDM cluster to access the MySQL database.
Creating a DWS Link¶
On the Cluster Management page, locate a cluster and click Job Management in the Operation column. On the displayed page, click the Links tab and then Create Link.
Select Data Warehouse Service and click Next to configure the DWS link parameters. Set the mandatory parameters listed in Table 2 and retain the default values for the optional parameters.
Table 2 DWS link parameters¶ Parameter
Description
Example Value
Name
Enter a unique link name.
dwslink
Database Server
IP address or domain name of the DWS database
192.168.0.3
Port
DWS database port
8000
Database Name
Name of the DWS database
db_demo
Username
User who has the read, write, and delete permissions on the DWS database
dbadmin
Password
Password of the user
-Use Agent
Whether to extract data from the data source through an agent
Yes
Agent
Click Select and select the created agent.
-Import Mode
COPY: Migrate the source data to the DWS management node and then copy the data to DataNodes. To access DWS through the Internet, select COPY.
COPY
Click Save.
Creating a Migration Job¶
Choose Table/File Migration > Create Job to create a job for exporting data from the MySQL database to DWS.
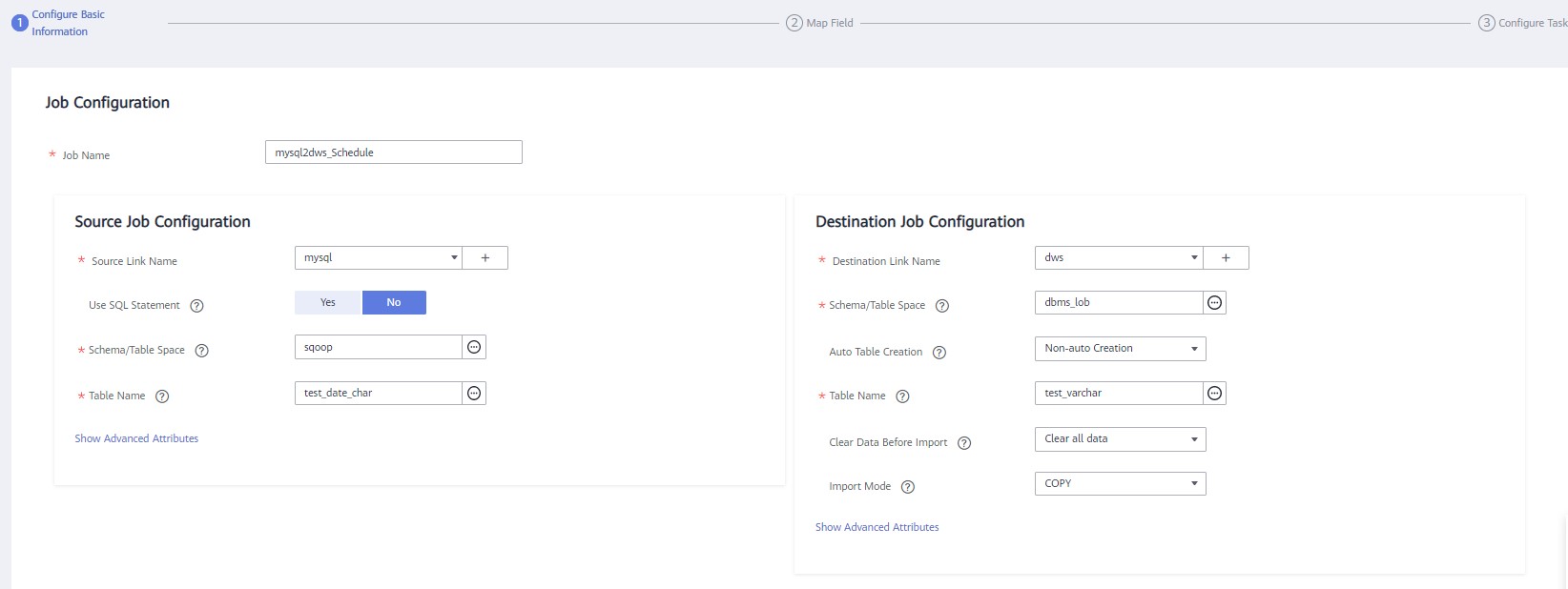
Figure 2 Creating a job for migrating data from MySQL to DWS¶
Job Name: Enter a unique name.
Source Job Configuration
Source Link Name: Select the mysqllink created in Creating a MySQL Link.
Use SQL Statement: Select No.
Schema/Tablespace: name of the schema or tablespace from which data is to be extracted
Table Name: name of the table from which data is to be extracted
Retain the default values of other optional parameters.
Destination Job Configuration
Destination Link Name: Select the dwslink created in Creating a DWS Link.
Schema/Tablespace: Select the DWS database to which data is to be written.
Auto Table Creation: This parameter is displayed only when both the migration source and destination are relational databases.
Table Name: Name of the table to which data is to be written. You can enter a table name that does not exist. CDM automatically creates the table in DWS.
isCompress: whether to compress data. If you select Yes, high-level compression will be performed. CDM applies to compression scenarios where the I/O read/write volume is large and the CPU is sufficient (the computing load is relatively low).
Orientation: You can create row- or column-store tables as needed. Generally, if a table contains many columns (called a wide table) and its query involves only a few columns, column storage is recommended. If a table contains only a few columns and a query includes most of the fields, row storage is recommended.
Extend char length: If the data encoding formats of the migration source and destination are different, the character length of the automatic table creation may be insufficient. If you select Yes for this parameter, the character length will be increased by three times during automatic table creation.
Clear Data Before Import: whether to clear data in the destination table before the migration task starts.
Click Next. The Map Field page is displayed. CDM automatically matches the source and destination fields, as shown in Figure 3.
If the field mapping is incorrect, you can drag the fields to adjust the mapping.
The expressions in CDM support field conversion of common character strings, dates, and values.
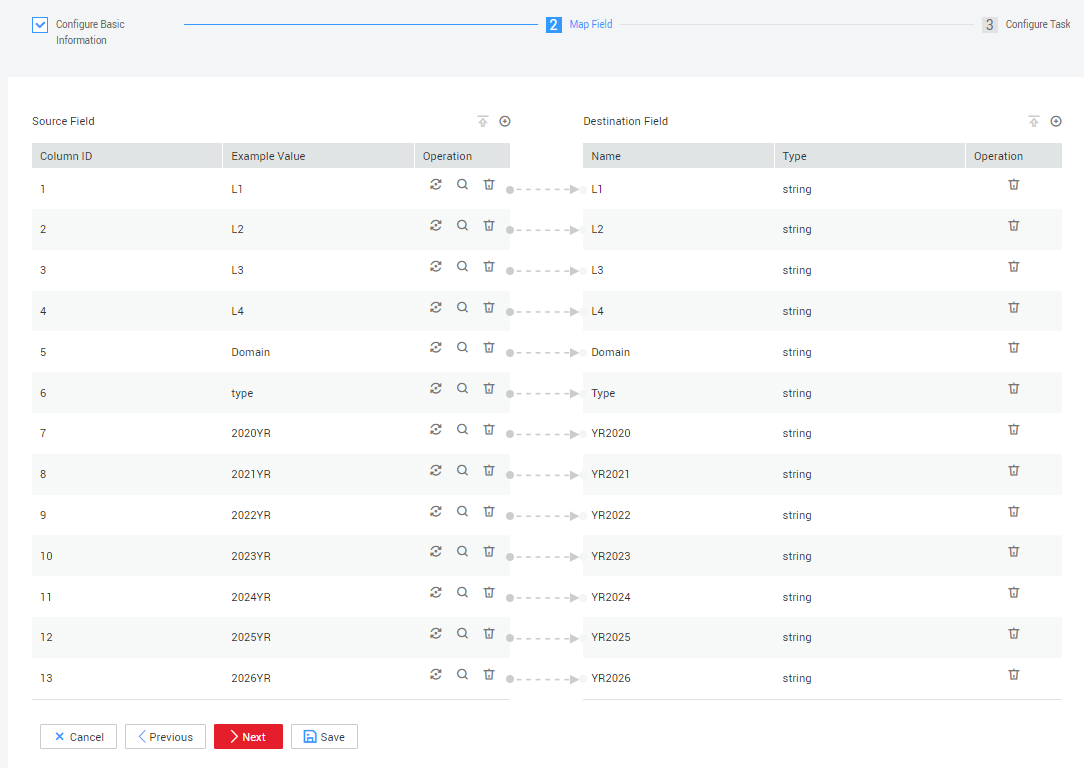
Figure 3 Table-to-table field mapping¶
Click Next and set task parameters. Generally, retain the default values of all parameters.
In this step, you can configure the following optional functions:
Retry Upon Failure: If the job fails to be executed, you can determine whether to automatically retry. Retain the default value Never.
Group: Select the group to which the job belongs. The default group is DEFAULT. On the Job Management page, jobs can be displayed, started, or exported by group.
Schedule Execution: Enable it if you need to configure scheduled jobs. Retain the default value No.
Concurrent Extractors: Enter the number of extractors to be concurrently executed. You can increase the value of this parameter to improve migration efficiency.
Write Dirty Data: Dirty data may be generated during data migration between tables. You are advised to select Yes.
Delete Job After Completion: Retain the default value Do not delete.
Click Save and Run. The Job Management page is displayed, on which you can view the job execution progress and result.
After the job is successfully executed, in the Operation column of the job, click Historical Record to view the job's historical execution records and read/write statistics.
On the Historical Record page, click Log to view the job logs.