Developing a DLI Spark Job¶
This section introduces how to develop a DLI Spark job on DataArts Factory.
Scenario Description¶
In most cases, SQL is used to analyze and process data when using Data Lake Insight (DLI). However, SQL is usually unable to deal with complex processing logic. In this case, Spark jobs can help. This section uses an example to demonstrate how to submit a Spark job on DataArts Factory.
The general submission procedure is as follows:
Create a DLI cluster and run a Spark job using physical resources of the DLI cluster.
Obtain a demo JAR package of the Spark job and associate with the JAR package on DataArts Factory.
Create a DataArts Factory job and submit it using the DLI Spark node.
Preparations¶
Object Storage Service (OBS) has been enabled and a bucket, for example, obs://dlfexample, has been created for storing the JAR package of the Spark job.
DLI has been enabled, and the Spark cluster spark_cluster has been created for providing physical resources required for the Spark job.
Obtaining Spark Job Code¶
The Spark job code used in this example comes from the maven repository that can be download from https://repo.maven.apache.org/maven2/org/apache/spark/spark-examples_2.10/1.1.1/spark-examples_2.10-1.1.1.jar. This Spark job is to calculate the approximate value of Pi.
After obtaining the JAR package of the Spark job codes, upload it to the OBS bucket. The save path is obs://dlfexample/spark-examples_2.10-1.1.1.jar.
On the DataArts Studio console, locate a workspace and click DataArts Factory.
In the navigation tree on the left, choose Configuration > Manage Resource. Click Create Resource and create resource spark-example on DataArts Factory and associate it with the JAR package obtained in 1.
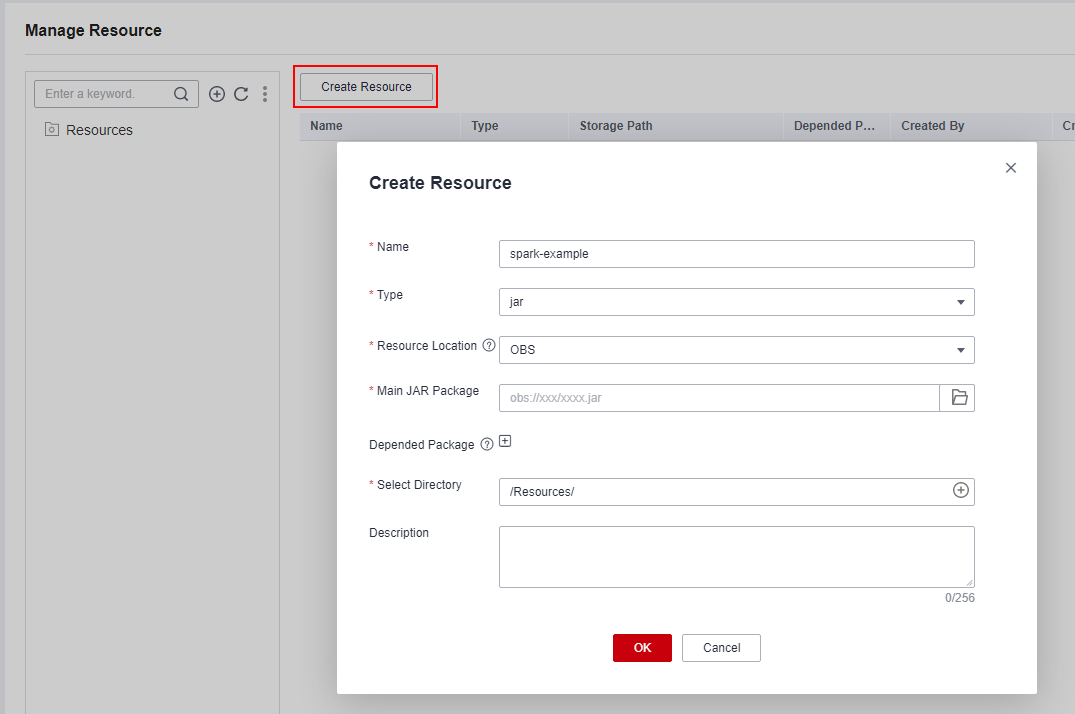
Figure 1 Creating a resource¶
Submitting a Spark Job¶
You need to create a job on DataArts Factory and submit the Spark job using the DLI Spark node of the job.
Create a job named job_DLI_Spark for the DataArts Factory module.
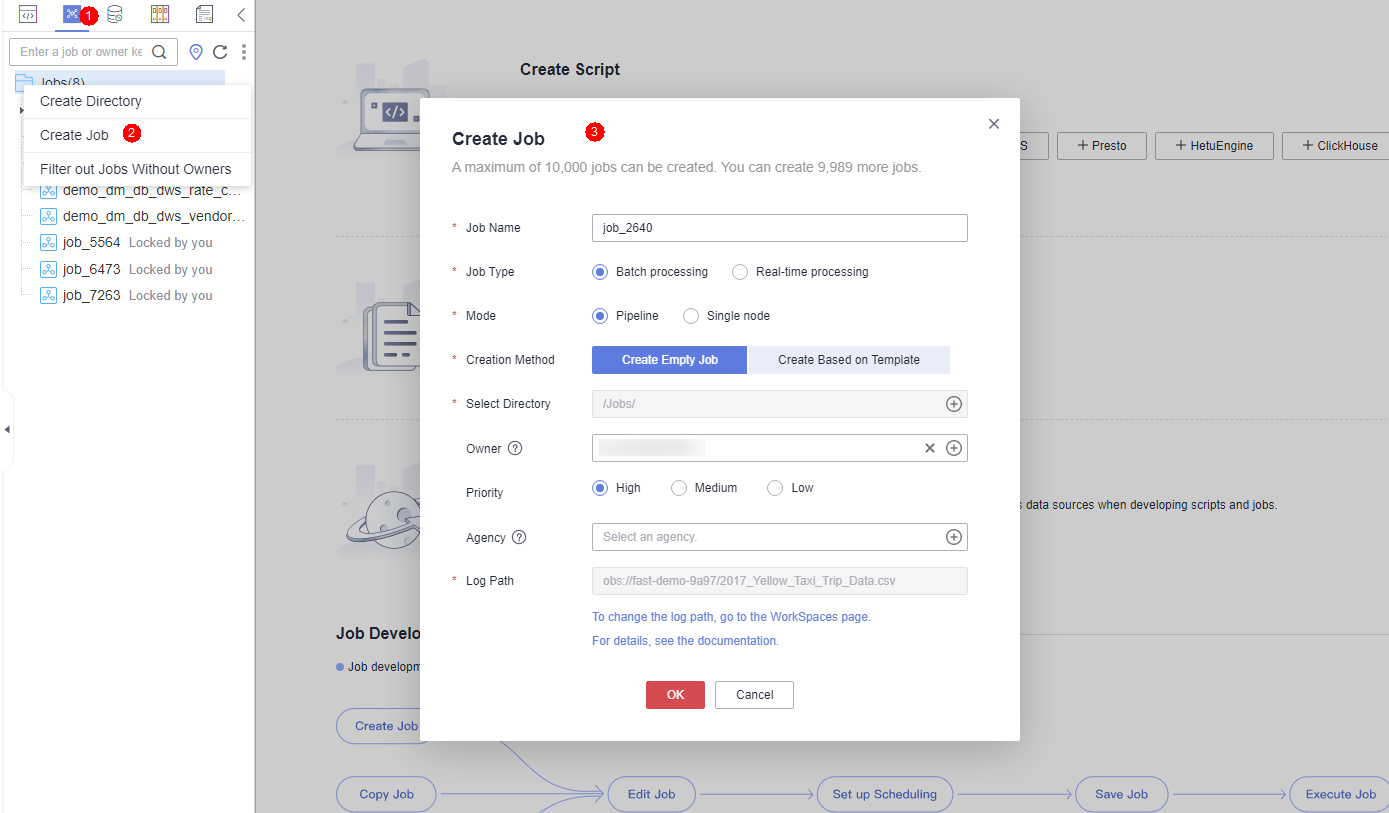
Figure 2 Creating a job¶
Go to the job development page, drag the DLI Spark node to the canvas, and click the node to configure node properties.
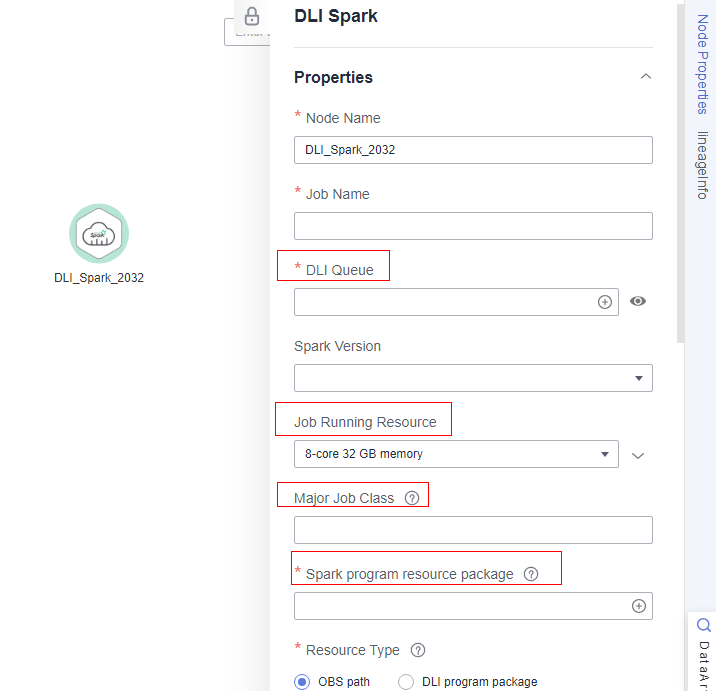
Figure 3 Configuring node properties¶
Description of key properties:
DLI Queue: Select a DLI queue.
Job Running Resource: Maximum CPU and memory resources that can be used when a DLI Spark node is running.
Major Job Class: major class of a DLI Spark node. In this example, the major class is org.apache.spark.examples.SparkPi.
Spark program resource package: Select the resources created in 3.
After the job orchestration is complete, click
 to test the job.
to test the job.
Figure 4 Job logs (for reference only)¶
If no error is recorded in logs, save and submit the job.