Functions¶
DataArts Migration: Efficient Ingestion of Multiple Heterogeneous Data Sources¶
DataArts Migration can help you seamlessly migrate batch data between 30+ homogeneous or heterogeneous data sources. You can use it to ingest data from both on-premises and cloud-based data sources, including file systems, relational databases, data warehouses, NoSQL databases, big data services, and object storage.
DataArts Migration uses a distributed compute framework and concurrent processing techniques to help you migrate enterprise data in batches without any downtime and rapidly build desired data structures.
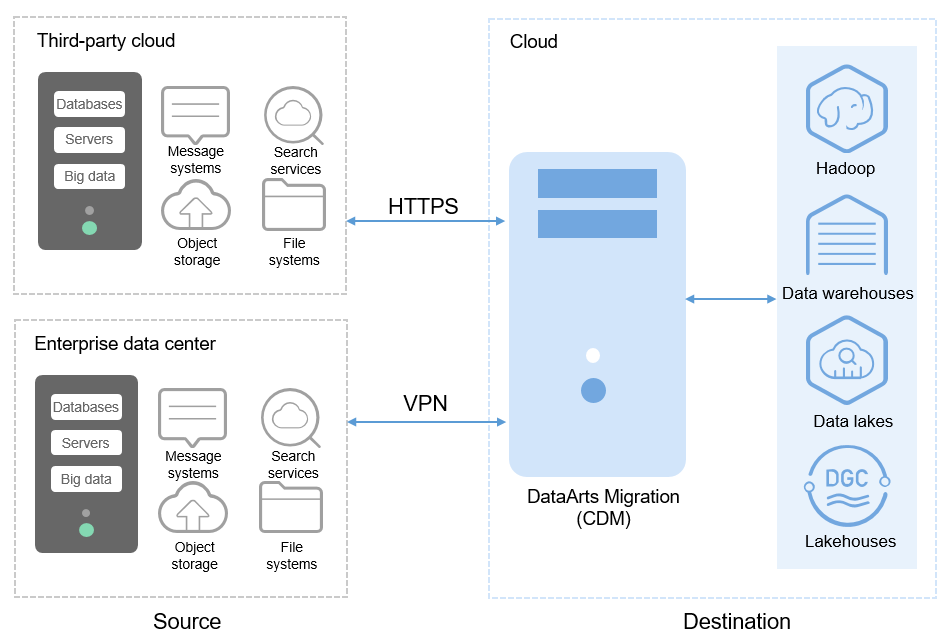
Figure 1 DataArts Migration¶
You can manage data on the wizard-based task management page. You can easily create data migration tasks that meet your requirements. DataArts Migration provides the following functions:
Table/File/Entire DB migration
You can migrate tables or files in batches, and migrate an entire database between homogeneous and heterogeneous database systems. You can include hundreds of tables in a single job.
Incremental data migration
You can migrate files, relational databases, and HBase in an incremental manner. You can perform incremental data migration by using WHERE clauses and variables of date and time.
Migration in transaction mode
When a batch data migration job fails to be executed, data will be rolled back to the state before the job started and data in the destination table will be automatically deleted.
Field conversion
Field conversion includes anonymization, character string operations, and date operations.
File encryption
You can encrypt files that are migrated to a cloud-based file system in batches.
MD5 verification
MD5 is used to check file consistency from end to end.
Dirty data archiving
Data that fails to be processed during migration, is filtered out and is not compliant with conversion or cleansing rules is recorded in dirty data logs. You can easily analyze abnormal data. You can also set a threshold for the dirty data ratio to determine whether a task is successful.
DataArts Factory: One-stop Collaborative Development¶
DataArts Factory provides an intuitive UI and built-in development methods for script and job development. DataArts Factory also supports fully hosted job scheduling, O&M, and monitoring, and incorporates industry data processing pipelines. You can create data development jobs in a few steps, and the entire process is visual. Online jobs can be jointly developed by multiple users. You can use DataArts Factory to manage big data cloud services and quickly build a big data processing center.
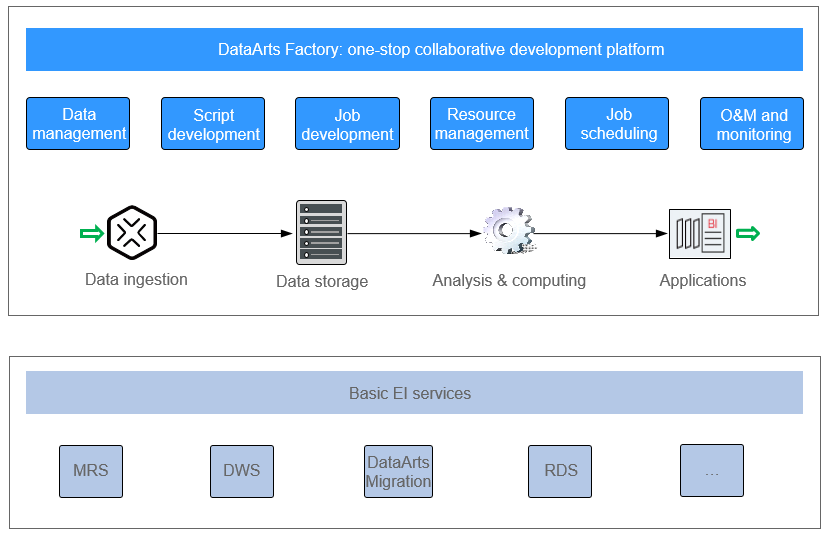
Figure 2 DataArts Factory architecture¶
DataArts Factory allows you to manage data, develop scripts, and schedule and monitor jobs. Data analysis and processing are easier than ever before.
Data management
You can manage multiple types of data warehouses, such as GaussDB (DWS), DLI, and MRS Hive.
You can use the graphical interface and data definition language (DDL) to manage database tables.
Script development
Provides an online script editor that allows more than one operator to collaboratively develop and debug SQL, Python, and Shell scripts online.
You can use Variables.
Job development
DataArts Factory provides a graphical designer that allows you to rapidly develop workflows through drag-and-drop and build data processing pipelines.
DataArts Factory is preset with multiple task types such as data integration, SQL, and Shell. Data is processed and analyzed based on task dependencies.
You can import and export jobs.
Resource management
You can centrally manage file, jar, and archive resources used during script and job development.
Job scheduling
You can schedule jobs to run once or recursively and use events to trigger scheduling jobs.
Job scheduling supports a variety of hybrid orchestration tasks. The high-performance scheduling engine has been tested by hundreds of applications.
O&M and monitoring
You can run, suspend, restore, or terminate a job.
You can view the operation details of each job and each node in the job.
You can use various methods to receive notifications when a job or task error occurs.