Performing Rolling Upgrade for Nodes¶
Scenario¶
In a rolling upgrade, a new node is created, existing workloads are migrated to the new node, and then the old node is deleted. Figure 1 shows the migration process.
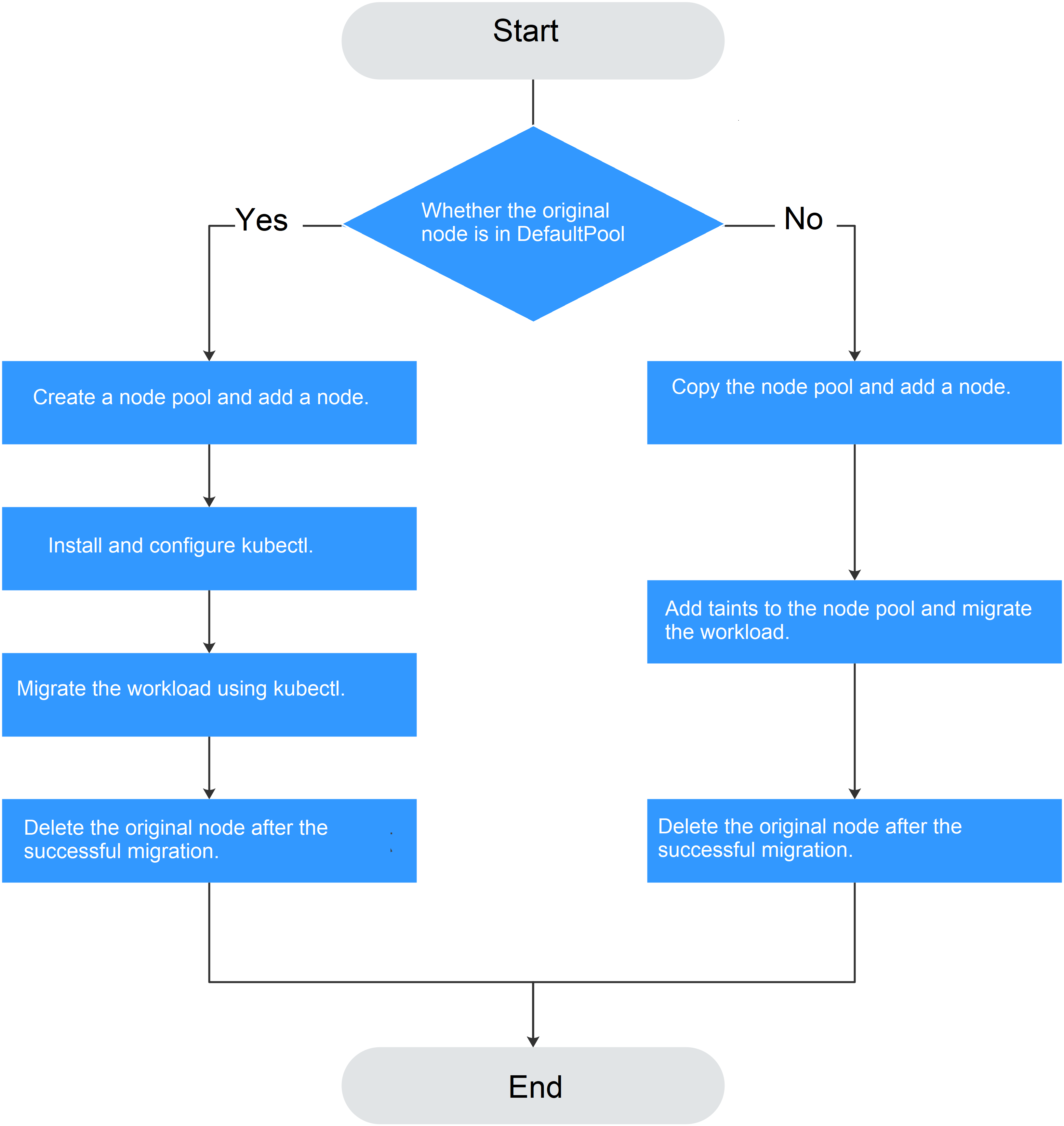
Figure 1 Workload migration¶
Notes and Constraints¶
The original node and the target node to which the workload is to be migrated must be in the same cluster.
The cluster must be of v1.13.10 or later.
The default node pool does not support this configuration.
Procedure If the Original Node Is in the Default Pool¶
Create a node pool. For details, see Creating a Node Pool.
On the node pool list page, click View Node in the Operation column of the target node pool. The IP address of the new node is displayed in the node list.
Install and configure kubectl. For details, see Accessing a Cluster Using kubectl.
Migrate the workload.
Add a taint to the node where the workload needs to be migrated out.
kubectl taint node [node] key=value:[effect]
In the preceding command, [node] indicates the IP address of the node where the workload to be migrated is located. The value of [effect] can be NoSchedule, PreferNoSchedule, or NoExecute. In this example, set this parameter to NoSchedule.
NoSchedule: Pods that do not tolerate this taint are not scheduled on the node; existing pods are not evicted from the node.
PreferNoSchedule: Kubernetes tries to avoid scheduling pods that do not tolerate this taint onto the node.
NoExecute: A pod is evicted from the node if it is already running on the node, and is not scheduled onto the node if it is not yet running on the node.
Note
To reset a taint, run the kubectl taint node [node] key:[effect]- command to remove the taint.
Safely evicts the workload on the node.
kubectl drain [node]
In the preceding command, [node] indicates the IP address of the node where the workload to be migrated is located.
In the navigation pane of the CCE console, choose Workloads > Deployments. In the workload list, the status of the workload to be migrated changes from Running to Unready. If the workload status changes to Running again, the migration is successful.
Note
During workload migration, if node affinity is configured for the workload, the workload keeps displaying a message indicating that the workload is not ready. In this case, click the workload name to go to the workload details page. On the Scheduling Policies tab page, delete the affinity configuration of the original node and configure the affinity and anti-affinity policies of the new node. For details, see Configuring Node Affinity Scheduling (nodeAffinity).
After the workload is migrated, you can view that the workload has been migrated to the node created in 1 on the Pods tab page of the workload details page.
Delete the original node.
After the workload is successfully migrated and runs properly, delete the original node.
Procedure If the Original Node Is Not in the Default Pool¶
Copy the node pool and add nodes to it. For details, see Copying a Node Pool.
Click View Node in the Operation column of the node pool. The IP address of the new node is displayed in the node list.
Migrate the workload.
Click Edit on the right of original node pool and configure Taints.
Enter the key and value of a taint. The options of Effect are NoSchedule, PreferNoSchedule, and NoExecute. Select NoExecute and click Add.
NoSchedule: Pods that do not tolerate this taint are not scheduled on the node; existing pods are not evicted from the node.
PreferNoSchedule: Kubernetes tries to avoid scheduling pods that do not tolerate this taint onto the node.
NoExecute: A pod is evicted from the node if it is already running on the node, and is not scheduled onto the node if it is not yet running on the node.
Note
To reset the taint, delete the configured one.
Click OK.
In the navigation pane of the CCE console, choose Workloads > Deployments. In the workload list, the status of the workload to be migrated changes from Running to Unready. If the workload status changes to Running again, the migration is successful.
Note
During workload migration, if node affinity is configured for the workload, the workload keeps displaying a message indicating that the workload is not ready. In this case, click the workload name to go to the workload details page. On the Scheduling Policies tab page, delete the affinity configuration of the original node and configure the affinity and anti-affinity policies of the new node. For details, see Configuring Node Affinity Scheduling (nodeAffinity).
After the workload is migrated, you can view that the workload has been migrated to the node created in 1 on the Pods tab page of the workload details page.
Delete the original node.
After the workload is successfully migrated and runs properly, delete the original node.