Creating a Scheduled CronHPA Policy¶
There are predictable and unpredictable traffic peaks for some services. For such services, CCE CronHPA allows you to scale resources in fixed periods. It can work with HPA policies to periodically adjust the HPA scaling scope, implementing workload scaling.
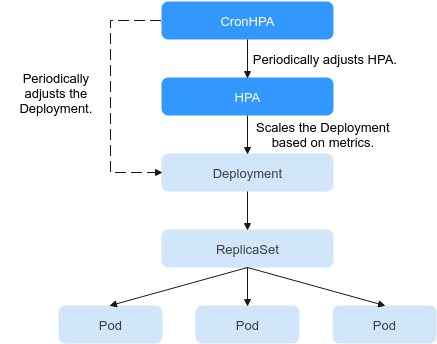
CronHPA can periodically adjust the maximum and minimum numbers of pods in the HPA policy or directly adjust the number of pods of a Deployment.
Prerequisites¶
CCE Advanced HPA of v1.2.13 or later has been installed in the cluster.
Using CronHPA to Adjust the HPA Scaling Scope¶
CronHPA can periodically scale out/in pods in HPA policies to satisfy complex services.
HPA and CronHPA associate scaling objects using the scaleTargetRef field. If a Deployment is the scaling object for both CronHPA and HPA, the two scaling policies are independent of each other. The operation performed later overwrites the operation performed earlier. As a result, the scaling effect does not meet the expectation.
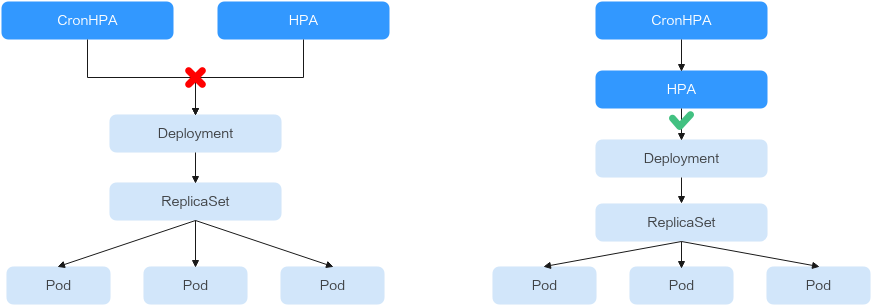
When CronHPA and HPA are used together, CronHPA rules take effect based on the HPA policy. CronHPA uses HPA to perform operations on the Deployment. Understanding the following parameters can better understand the working rules of the CronHPA.
targetReplicas: number of pods set for CronHPA. When CronHPA takes effect, this parameter adjusts the maximum or minimum number of pods in HPA policies to adjust the number of Deployment pods.
minReplicas: minimum number of Deployment pods.
maxReplicas: maximum number of Deployment pods.
replicas: number of pods in a Deployment before the CronHPA policy takes effect.
When a CronHPA rule is triggered, the maximum or minimum number of pods is adjusted by comparing the targetReplicas value with the actual pod count, while also considering the HPA policy's minimum or maximum pod limits.
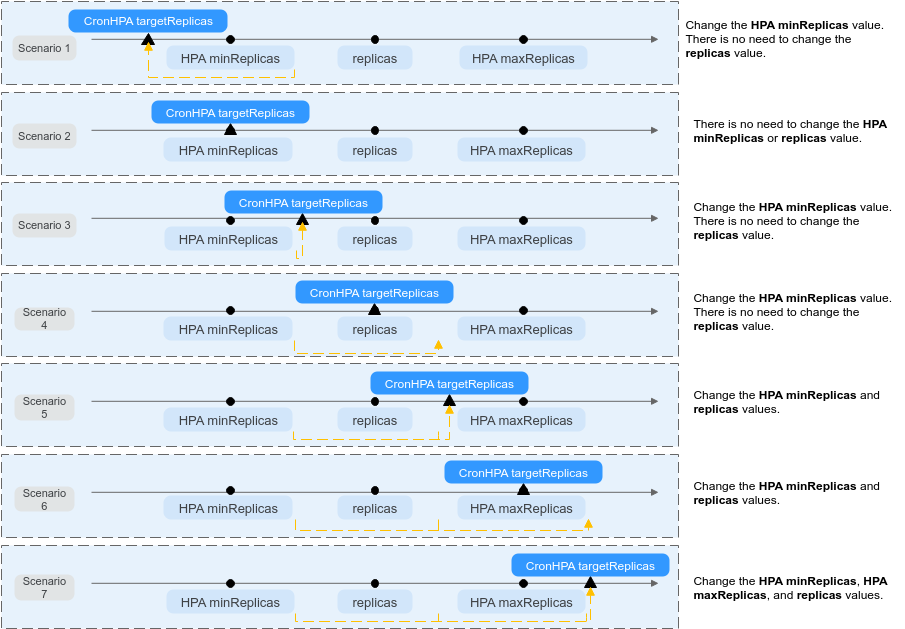
Figure 1 CronHPA scaling scenarios¶
Figure 1 shows possible scaling scenarios. The following examples detail how CronHPA modifies the number of pods in HPAs.
Scenario | Scenario Description | Scaling Condition | Result | Operation Description | ||
|---|---|---|---|---|---|---|
Target CronHPA Pods (targetReplicas) | Deployment Pods (replicas) | Upper and Lower Limits of HPA Pods (minReplicas/maxReplicas) | ||||
1 | targetReplicas < minReplicas <= replicas <= maxReplicas | 4 | 5 | 5/10 | HPA: 4/10 Deployment: 5 | When the value of targetReplicas is smaller than that of minReplicas:
|
2 | targetReplicas = minReplicas <= replicas <= maxReplicas | 5 | 6 | 5/10 | HPA: 5/10 Deployment: 6 | When the value of targetReplicas is equal to that of minReplicas:
|
3 | minReplicas < targetReplicas < replicas <= maxReplicas | 4 | 5 | 1/10 | HPA: 4/10 Deployment: 5 | When the value of targetReplicas is greater than that of minReplicas and smaller than that of replicates:
|
4 | minReplicas < targetReplicas = replicas < maxReplicas | 5 | 5 | 1/10 | HPA: 5/10 Deployment: 5 | When the value of targetReplicas is greater than that of minReplicas and equal to that of replicates:
|
5 | minReplicas <= replicas < targetReplicas < maxReplicas | 6 | 5 | 1/10 | HPA: 6/10 Deployment: 6 | When the value of targetReplicas is greater than that of replicates and less than that of maxReplicas:
|
6 | minReplicas <= replicas < targetReplicas = maxReplicas | 10 | 5 | 1/10 | HPA: 10/10 Deployment: 10 | When the value of targetReplicas is greater than that of replicates and equal to that of maxReplicas:
|
7 | minReplicas <= replicas <= maxReplicas < targetReplicas | 11 | 5 | 5/10 | HPA: 11/11 Deployment: 11 | When the value of targetReplicas is greater than that of maxReplicas:
|
Using the CCE console
Log in to the CCE console and click the cluster name to access the cluster console.
Choose Workloads in the navigation pane. Locate the target workload and choose More > Auto Scaling in the Operation column.
Set Policy Type to HPA+CronHPA and enable HPA and CronHPA policies.
CronHPA periodically adjusts the maximum and minimum numbers of pods using the HPA policy.
Configure the HPA policy. For details, see Creating an HPA Policy.
Table 2 HPA policy¶ Parameter
Description
Pod Range
Minimum and maximum numbers of pods.
When a policy is triggered, the workload pods are scaled within this range.
Cooldown Period
Interval between a scale-in and a scale-out. The unit is minute. The interval cannot be shorter than 1 minute.
This parameter is supported only in clusters of v1.15 to v1.23.
This parameter indicates the interval between consecutive scaling operations. The cooldown period ensures that a scaling operation is initiated only when the previous one is completed and the system is running stably.
Scaling Behavior
This parameter is supported only in clusters of v1.25 or later.
Default: scales workloads using the Kubernetes default behavior. For details, see Default Behavior.
Custom: scales workloads using custom policies such as stabilization window, steps, and priorities. Unspecified parameters use the values recommended by Kubernetes.
Disable scale-out/scale-in: Select whether to disable scale-out or scale-in.
Stabilization Window: a period during which CCE continuously checks whether the metrics used for scaling keep fluctuating. CCE triggers scaling if the desired state is not maintained for the entire window. This window restricts the unwanted flapping of pod count due to metric changes.
Step: specifies the scaling step. You can set the number or percentage of pods to be scaled in or out within a specified period. If there are multiple policies, you can select the policy that maximizes or minimizes the number of pods.
System Policy
Metric: You can select CPU usage or Memory usage.
Note
Usage = Average resource usage of all pods in a workload/Requested resources
Desired Value: Enter the desired average resource usage.
This parameter indicates the desired value of the selected metric. Number of target pods (rounded up) = (Current metric value/Desired value) x Number of current pods
Note
When calculating the number of pods to be added or reduced, the HPA policy uses the maximum number of pods in the last 5 minutes.
Tolerance Range: Scaling is not triggered when the metric value is within the tolerance range. The desired value must be within the tolerance range.
If the metric value is greater than the scale-in threshold and less than the scale-out threshold, no scaling is triggered. This parameter is supported only in clusters of v1.15 or later.
Custom Policy (supported only in clusters of v1.15 or later)
Note
Before creating a custom policy, install an add-on that supports custom metric collection (for example, Prometheus) in the cluster. Ensure that the add-on can collect and report the custom metrics of the workloads.
For details, see Monitoring Custom Metrics Using Cloud Native Cluster Monitoring.
Metric Name: name of the custom metric. You can select a name as prompted.
Metric Source: Select an object type from the drop-down list. You can select Pod.
Desired Value: the average metric value of all pods. Number of pods to be scaled (rounded up) = (Current metric value/Desired value) x Number of current pods
Note
When calculating the number of pods to be added or reduced, the HPA policy uses the maximum number of pods in the last 5 minutes.
Tolerance Range: Scaling is not triggered when the metric value is within the tolerance range. The desired value must be within the tolerance range.
Click
 in the CronHPA policy rule. In the dialog box displayed, configure scaling policy parameters.
in the CronHPA policy rule. In the dialog box displayed, configure scaling policy parameters.Table 3 CronHPA policy parameters¶ Parameter
Description
Target Instances
When the policy is triggered, CCE will adjust the number of HPA policy pods based on service requirements. For details, see Table 1.
Trigger Time
You can select a specific time every day, every week, every month, or every year.
Note
This time indicates the local time of where the node is deployed.
Enable
Enable or disable the policy rule.
After configuring the preceding parameters, click OK. Then, the added policy rule is displayed in the rule list. Repeat the preceding steps to add a maximum of 10 policy rules, but the triggering time of these policies must be different.
Click Create.
Using kubectl
When the CronHPA is compatible with the HPA policy, the scaleTargetRef field in CronHPA must be set to the HPA policy, and the scaleTargetRef field in the HPA policy must be set to Deployment. In this way, CronHPA adjusts the maximum and minimum numbers of pods in the HPA policy at a fixed time and the scheduled scaling is compatible with the auto scaling.
Create an HPA policy for the Deployment.
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: hpa-test namespace: default spec: maxReplicas: 10 # Maximum number of pods minReplicas: 5 # Minimum number of pods scaleTargetRef: # Associate a Deployment. apiVersion: apps/v1 kind: Deployment name: nginx targetCPUUtilizationPercentage: 50
Create a CronHPA policy and associate it with the HPA policy created in 1.
apiVersion: autoscaling.cce.io/v2alpha1 kind: CronHorizontalPodAutoscaler metadata: name: ccetest namespace: default spec: scaleTargetRef: # Associate an HPA policy. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler name: hpa-test rules: - ruleName: "scale-down" schedule: "15 * * * *" # Running time and period of a job. For details, see Cron, for example, 0 * * * * or @hourly. targetReplicas: 1 # Number of target pods disable: false - ruleName: "scale-up" schedule: "13 * * * *" targetReplicas: 11 disable: false
Table 4 Key fields of CronHPA¶ Field
Description
apiVersion
API version. The value is fixed at autoscaling.cce.io/v2alpha1.
kind
API type. The value is fixed at CronHorizontalPodAutoscaler.
metadata.name
Name of a CronHPA policy.
metadata.namespace
Namespace to which the CronHPA policy belongs.
spec.scaleTargetRef
Specifies the scaling object of CronHPA. The following fields can be configured:
apiVersion: API version of the CronHPA scaling object.
kind: API type of the CronHPA scaling object.
name: Name of the CronHPA scaling object.
CronHPA supports HPA policies or Deployments. For details, see Using CronHPA to Adjust the HPA Scaling Scope or Using CronHPA to Directly Adjust the Number of Deployment Pods.
spec.rules
CronHPA policy rule. Multiple rules can be added. The following fields can be configured for each rule:
ruleName: CronHPA rule name, which must be unique.
schedule: Running time and period of a job. For details, see Cron, for example, 0 * * * * or @hourly.
Note
This time indicates the local time of where the node is deployed.
targetReplicas: indicates the number of pods to be scaled in or out.
disable: The value can be true or false. false indicates that the rule takes effect, and true indicates that the rule does not take effect.
Using CronHPA to Directly Adjust the Number of Deployment Pods¶
CronHPA adjusts associated Deployments separately to periodically adjust the number of Deployment pods. The method is as follows:
Using the CCE console
Log in to the CCE console and click the cluster name to access the cluster console.
Choose Workloads in the navigation pane. Locate the target workload and choose More > Auto Scaling in the Operation column.
Set Policy Type to HPA+CronHPA, disable HPA, and enable CronHPA.
CronHPA periodically adjusts the number of workload pods.
Click
 in the CronHPA policy rule. In the dialog box displayed, configure scaling policy parameters.
in the CronHPA policy rule. In the dialog box displayed, configure scaling policy parameters.Table 5 CronHPA policy parameters¶ Parameter
Description
Target Instances
When a policy is triggered, the number of workload pods will be adjusted to the value of this parameter.
Trigger Time
You can select a specific time every day, every week, every month, or every year.
Note
This time indicates the local time of where the node is deployed.
Enable
Enable or disable the policy rule.
After configuring the preceding parameters, click OK. Then, the added policy rule is displayed in the rule list. Repeat the preceding steps to add multiple policy rules, but the triggering time of the policies must be different.
Click Create.
Using kubectl
apiVersion: autoscaling.cce.io/v2alpha1
kind: CronHorizontalPodAutoscaler
metadata:
name: ccetest
namespace: default
spec:
scaleTargetRef: # Associate a Deployment.
apiVersion: apps/v1
kind: Deployment
name: nginx
rules:
- ruleName: "scale-down"
schedule: "08 * * * *" # Running time and period of a job. For details, see Cron, for example, 0 * * * * or @hourly.
targetReplicas: 1
disable: false
- ruleName: "scale-up"
schedule: "05 * * * *"
targetReplicas: 3
disable: false