Node Scaling Rules¶
HPA is designed for pod-level scaling and can dynamically adjust the number of replicas based on workload metrics. However, if cluster resources are insufficient and new replicas cannot run, you can only scale out the cluster.
CCE Cluster Autoscaler is a node scaling component provided by Kubernetes. It automatically scales in or out nodes in a cluster based on the pod scheduling status and resource usage. It supports multiple scaling modes, such as multi-AZ, multi-pod-specifications, metric triggering, and periodic triggering, to meet the requirements of different node scaling scenarios.
Prerequisites¶
Before using the node scaling function, you must install the CCE Cluster Autoscaler add-on of v1.13.8 or later in the cluster.
How Cluster Autoscaler Works¶
Cluster Autoscaler goes through two processes.
Scale-out: Autoscaler checks all unscheduled pods every 10 seconds and selects a node pool that meets the requirements for scale-out based on the policy you set.
Note
When Autoscaler checks unscheduled pods for scale outs, it uses the scheduling algorithm consistent with the Kubernetes community version for simulated scheduling calculation. If non-built-in kube-schedulers or other non-Kubernetes community scheduling policies are used for application scheduling, when Autoscaler is used to expand the capacity for such applications, the capacity may fail to be expanded or may be expanded more than expected due to inconsistent scheduling algorithms.
Scale-in: Autoscaler scans all nodes every 10 seconds. If the number of pod requests on a node is less than the custom scale-in threshold (in percentage), Autoscaler will check whether pods on the current node can be migrated to other nodes.
When a cluster node is idle for a period of time (10 minutes by default), cluster scale-in is triggered, and the node is automatically deleted. However, a node cannot be deleted from a cluster if the following pods exist:
Pods that do not meet specific requirements set in Pod Disruption Budgets (PodDisruptionBudget)
Pods that cannot be scheduled to other nodes due to constraints such as affinity and anti-affinity policies
Pods that have the cluster-autoscaler.kubernetes.io/safe-to-evict: 'false' annotation
Pods (except those created by DaemonSets in the kube-system namespace) that exist in the kube-system namespace on the node
Pods that are not created by the controller (Deployment/ReplicaSet/job/StatefulSet)
Note
When a node meets the scale-in conditions, Autoscaler adds the DeletionCandidateOfClusterAutoscaler taint to the node in advance to prevent pods from being scheduled to the node. After the Autoscaler add-on is uninstalled, if the taint still exists on the node, manually delete it.
Cluster Autoscaler Architecture¶
Figure 1 shows the Cluster Autoscaler architecture and its core modules.
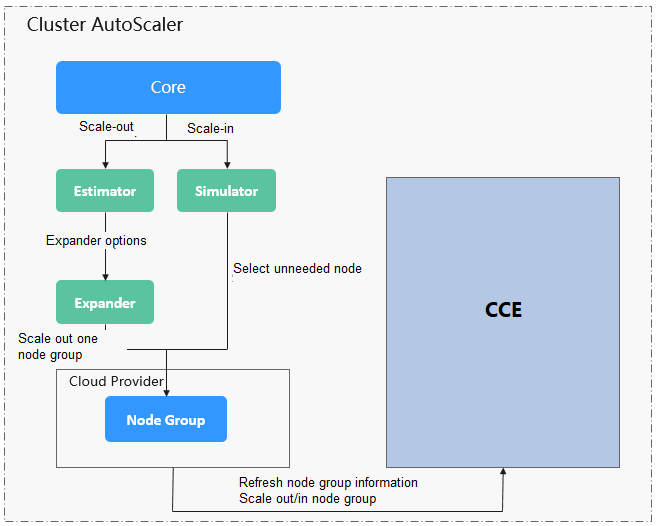
Figure 1 Cluster Autoscaler architecture¶
Description
Estimator: Evaluates the number of nodes to be added to each node pool to host unschedulable pods.
Simulator: Finds the nodes that meet the scale-in conditions in the scale-in scenario.
Expander: Selects an optimal node from the node pool picked out by the Estimator based on the user-defined policy in the scale-out scenario. Table 1 lists the Expander policies.
Table 1 Expander policies supported by CCE¶ Policy
Description
Application Scenario
Example
Random
Randomly selects a schedulable node pool to perform the scale-out.
This policy is typically used as a basic backup for other complex policies. Only use this policy if the other policies cannot be used.
Assume that auto scaling is enabled for node pools 1 and 2 in the cluster and the scale-out upper limit is not reached. The policy for scaling out the number of pods for a workload is as follows:
Pending pods trigger the Autoscaler to determine the scale-out process.
Autoscaler simulates the scheduling phase and evaluates that some pending pods can be scheduled to the added nodes in both node pools 1 and 2.
Autoscaler randomly selects node pool 1 or node pool 2 for scale-out.
most-pods
A combined policy. It takes precedence over the random policy.
Preferentially selects the node pool that can schedule the most pods after scale-out. If multiple node pools meet the condition, the random policy is used for further decision-making.
This policy is based on the maximum number of pods that can be scheduled.
Assume that auto scaling is enabled for node pools 1 and 2 in the cluster and the scale-out upper limit is not reached. The policy for scaling out the number of pods for a workload is as follows:
Pending pods trigger the Autoscaler to determine the scale-out process.
Autoscaler simulates the scheduling phase and evaluates that some pending pods can be scheduled to the added nodes in both node pools 1 and 2.
Autoscaler evaluates that node pool 1 can schedule 20 new pods and node pool 2 can schedule only 10 new pods after scale-out. Therefore, Autoscaler selects node pool 1 for scale-out.
least-waste
A combined policy. It takes precedence over the random policy.
Autoscaler evaluates the overall CPU or memory allocation rate of the node pools and selects the node pool with the minimum CPU or memory waste. If multiple node pools meet the condition, the random policy is used for further decision-making.
This policy uses the minimum waste score of CPU or memory resources as the selection criteria.
The formula for calculating the minimum waste score (wastedScore) is as follows:
wastedCPU = (Total number of CPUs of the nodes to be scaled out - Total number of CPUs of the pods to be scheduled)/Total number of CPUs of the nodes to be scaled out
wastedMemory = (Total memory size of nodes to be scaled out - Total memory size of pods to be scheduled)/Total memory size of nodes to be scaled out
wastedScore = wastedCPU + wastedMemory
Assume that auto scaling is enabled for node pools 1 and 2 in the cluster and the scale-out upper limit is not reached. The policy for scaling out the number of pods for a workload is as follows:
Pending pods trigger the Autoscaler to determine the scale-out process.
Autoscaler simulates the scheduling phase and evaluates that some pending pods can be scheduled to the added nodes in both node pools 1 and 2.
Autoscaler evaluates that the minimum waste score of node pool 1 after scale-out is smaller than that of node pool 2. Therefore, Autoscaler selects node pool 1 for scale-out.
priority
A combined policy. The priorities for the policies are as follows: priority > least-waste > random.
It is an enhanced least-waste policy configured based on the node pool or scaling group priority. If multiple node pools meet the condition, the least-waste policy is used for further decision-making.
This policy allows you to configure the priorities of node pools or scaling groups through the console or API, while the least-waste policy can effectively minimize resource waste in various scenarios. The priority policy is used as the default preferred policy thanks to its good universality.
Assume that auto scaling is enabled for node pools 1 and 2 in the cluster and the scale-out upper limit is not reached. The policy for scaling out the number of pods for a workload is as follows:
Pending pods trigger the Autoscaler to determine the scale-out process.
Autoscaler simulates the scheduling phase and evaluates that some pending pods can be scheduled to the added nodes in both node pools 1 and 2.
Autoscaler evaluates that node pool 1 has a higher priority than node pool 2. Therefore, Autoscaler selects node pool 1 for scale-out.
priority-ratio
A combined policy. The priorities for the policies are as follows: priority > priority-ratio > least-waste > random.
If there are multiple node pools with the same priority, evaluate the CPU to memory ratios for the nodes in the cluster. Then compare that ratio, for what was allocated to what had been requested. Finally, you should preferentially select the node pools where these two ratios are the closest.
This policy is used for rescheduling global resources for pods or nodes (instead of only adding nodes) to reduce the overall resource fragmentation rate of the cluster. Use this policy only in rescheduling scenarios.
Assume that auto scaling is enabled for node pools 1 and 2 in the cluster and the scale-out upper limit is not reached. The policy for scaling out the number of pods for a workload is as follows:
Pending pods trigger the Autoscaler to determine the scale-out process.
Autoscaler simulates the scheduling phase and evaluates that some pending pods can be scheduled to the added nodes in both node pools 1 and 2.
Autoscaler determines a preferentially selected node pool and evaluates that the CPU/memory ratio of pods is 1:4. The node flavor in node pool 1 is 2 vCPUs and 8 GiB of memory (the CPU/memory ratio is 1:4), and the node flavor in node pool 2 is 2 vCPUs and 4 GiB of memory (the CPU/memory ratio is 1:2). Therefore, node pool 1 is preferred for this scale-out.